


AI transfer learning introduction
One of the most remarkable properties of the way humans learn is our innate ability to generalise our experiences to new situations.
This can be observed in many ways e.g., avoiding a particular food that made us ill in the past. Or the way a child can use their knowledge of how to zip up a jacket and apply the same concept to zipping up their backpack.
It turns out that this type of generalising, i.e., the transferring of knowledge across situations, whilst common for most humans, is hard for AI models.
A practical consequence of this challenge is that often bespoke models must be trained for each use case, which can require expertise and resources that are often hard to find within an organisation.
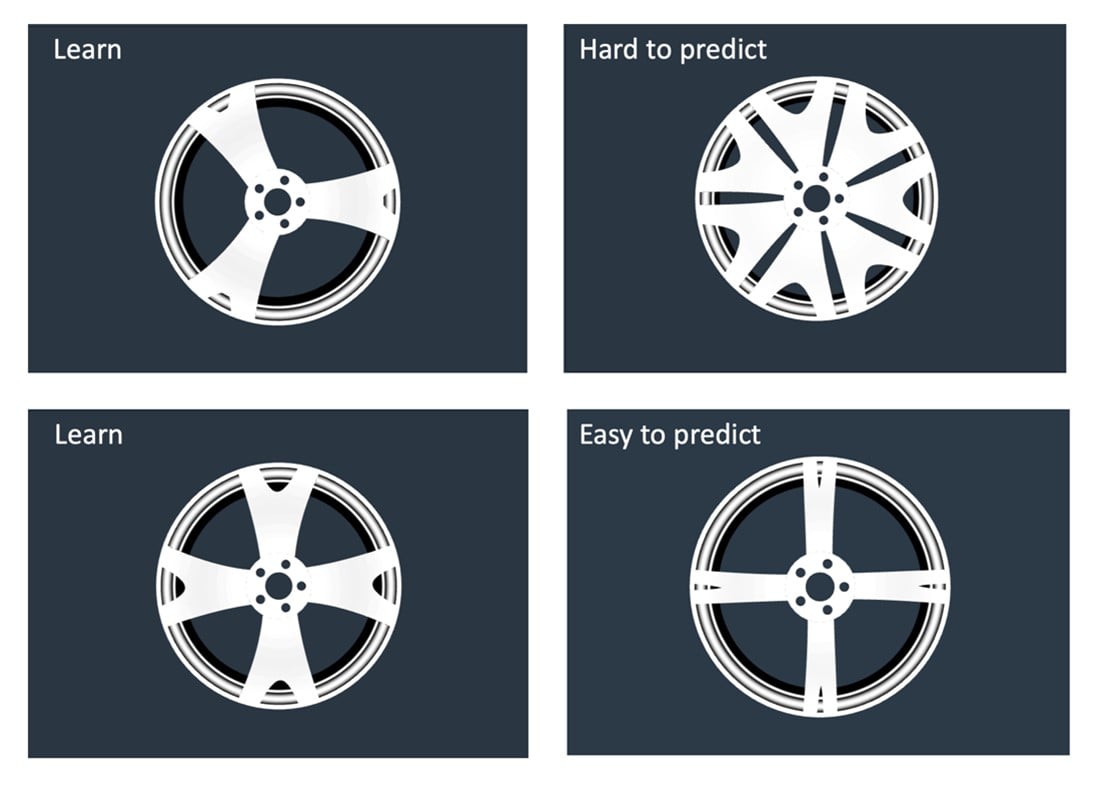
Figure 1: The specificity of AI models can mean that AI struggles to make sensible predictions for data that differ too much from the training data.
A sub-field of AI known as transfer learning is addressing this dilemma by attempting to develop models that can translate their experience from one use case to another.
Neural Networks are a model that has seen many applications of transfer learning in recent years.
Neural Networks (NNs), whilst not a new model, have come to prominence in the last decade with the meteoric rise of data volumes and complexity.
NNs power many of the modern-day AI applications such as real-time speech translation, autonomous vehicles and even analysing radiology images in hospitals to name just a few.
The smallest unit of a NN is called a neuron which has three parts: input connections, a core, and output connections.
Data inputs arrive through input connections, a mathematical operation is applied, and the results are sent to output connections.

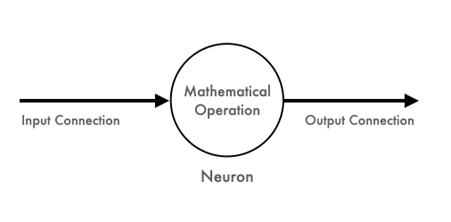
Figure 2: The canonical unit of a neural network is a single neuron that takes data, applies a mathematical operation, and passes it on.
It turns out that chaining many of these neurons into a network structure can create a highly flexible learning algorithm that can approximate any function given sufficient network size and data.
In general, the larger and more complex the data is the larger network required. Larger networks and data sizes also require a longer time to train.
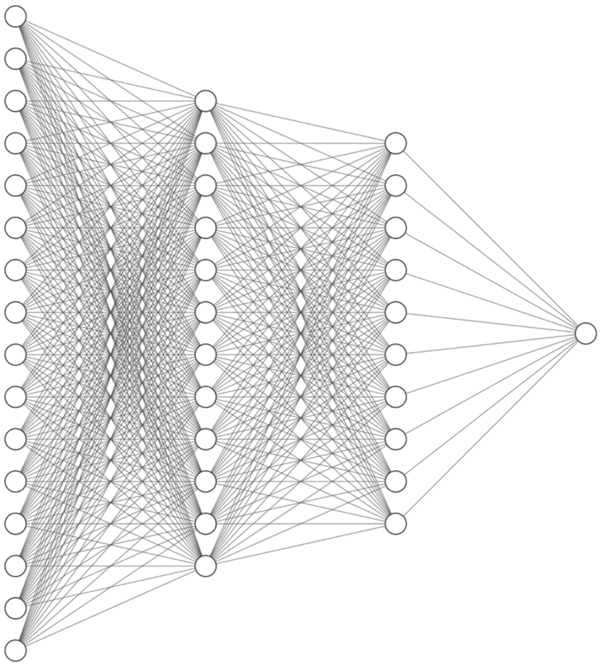
Figure 3: A neural network is comprised of a set of neurons that are connected in layers. Whilst individually, each neuron is quite simple, composing them together gives neural networks their immense ability to learn from complex data sources.
NNs are particularly amenable to transfer learning because a network can be trained on one use case, have their weights (the learned parameters of a NN model associated with each neuron) ‘frozen’, and then partially re-trained on a different but related task.
To borrow an example from the image classification domain, let’s say we wanted to build a model to classify tigers in pictures. Instead of starting from scratch, we might take a pre-trained generic image classifier trained on a large dataset.
Our hope is that this model will serve as a general model of the visual world.
The secondary, more specific model, aimed at detecting tigers, can then take advantage of all the features learned from the first model without needing to create a model from scratch on a large dataset.
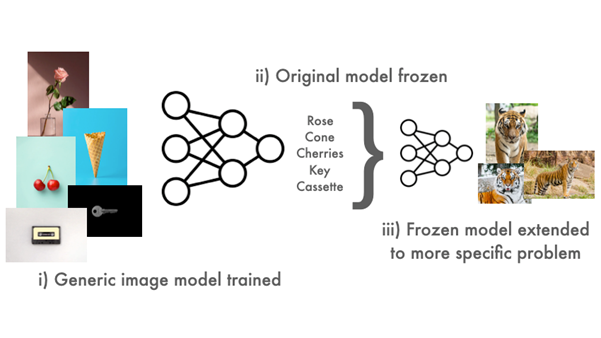
Figure 4: Transfer learning with NNs involves first training a generic model whose weights are then frozen before being further learned on a more specific task. The idea is that the second model can utilise learned features from the first.
Relating form to function
A common desire we see from engineers wanting to take advantage of AI is how to relate form to function. Put simply, can an AI model learn how changes to its design will affect its performance?
A concrete example would be understanding how the shape of a wind turbine's blades affects its downstream power coefficient.
Late changes in a design cycle if performance does not meet expectations can have costly implications.
How best to model such a problem using AI?
In the case of the wind turbine example, the inputs to the model consist of 3D turbine geometries (plus perhaps operating conditions e.g., wind speed) and output scalar values often quantities like power coefficient.
Such data is often accrued by engineers during simulations that are run during product development cycles.
A traditional deep learning approach (a term used to describe any approach using NNs with multiple layers) may lead us to train a model directly on the geometries themselves and predict the scalar output values.
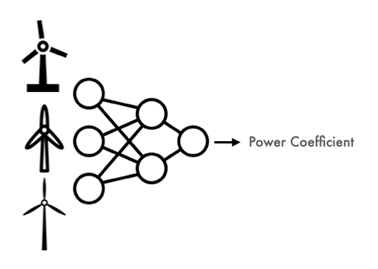
Figure 5: Using a NN to predict performance outputs directly is possible and perhaps even the optimal approach with sufficiently large training data but often engineering contexts lack the data required to make this work.
Whilst this makes sense theoretically, in practice, this type of formulation requires many training geometries, usually > 10k, a volume that often eludes most product development cycles where a more modest 100-500 geometries is considered a luxury.
In order to solve the above scenario, within the Monolith AI platform we often employ a two-tiered modelling approach consisting of an auto-encoder and a downstream predictive model.
Auto-encoders are a special type of neural network that, once trained, map high dimensional inputs e.g., 3D data, into a lower dimensional parameterisation that encodes much of the original information into a far smaller number of parameters.
An auto-encoder is trained by passing its input data through the network layers and attempting to recover the original geometries at the end of the network.
A key element of an auto-encoder is the ‘information bottleneck’ which is expressed in the network architecture as an intermediate hidden latent layer of the network that has a smaller number of variables than the input.
This compressed section of the network forces the model to keep only the most useful information that describes the geometries.
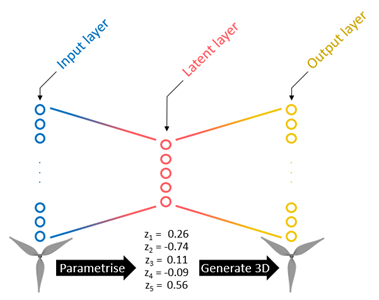
Figure 6: Autoencoders have a network architecture that contains a smaller dimension in the middle of the network which helps them to learn a lower dimensional representation of the data which can be useful for many purposes.
Autoencoders provide a general parametric description of the data.
They can be trained once, but utilised for multiple applications e.g., creating lower dimensional feature sets to train a downstream quantity of interest (QoI), measuring similarity between geometries, or generating new unseen geometries for exploring the conceptual design landscape.
Using autoencoders this way is a type of transfer learning.
Back to our wind turbine example. The benefit when an autoencoder is used along with a downstream model to predict scalar QoIs such as power coefficient, is that the training of the downstream model is greatly simplified as it has no need to re-learn the mesh parameterisation.
The downstream model selection can also be flexible, for example it could be a different machine learning technique entirely (such as linear regression or a random forest) or be in the form of additional layers added to the end of the auto-encoder's network.
The latter technique is often used in image and language models, to adapt large, general, models for specific tasks as per the tiger classification example earlier.
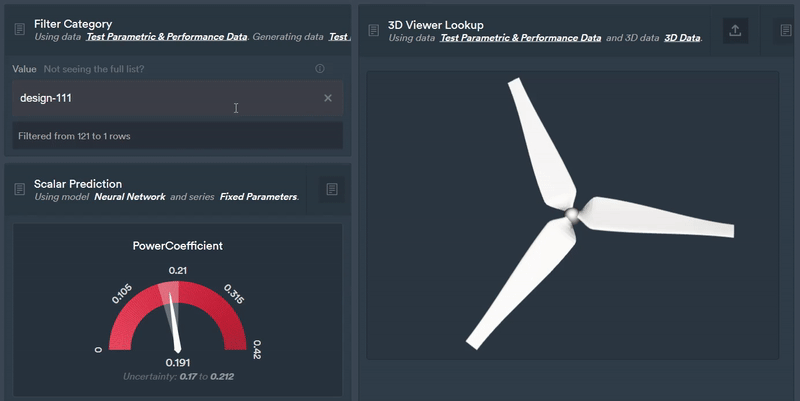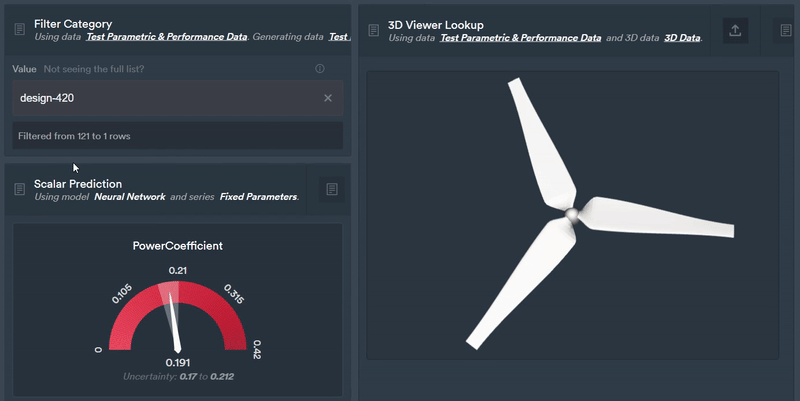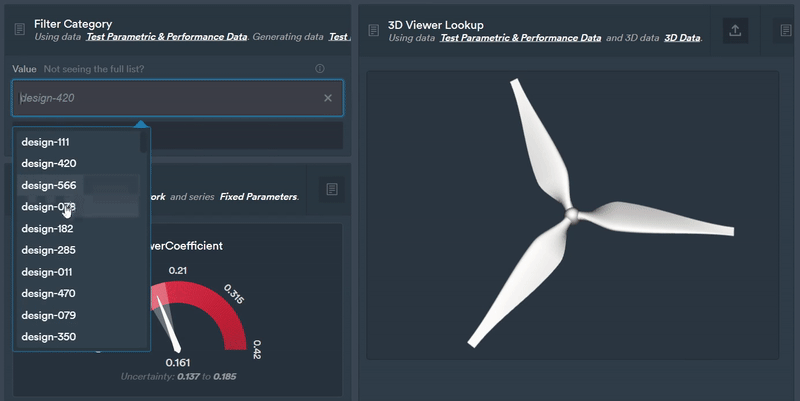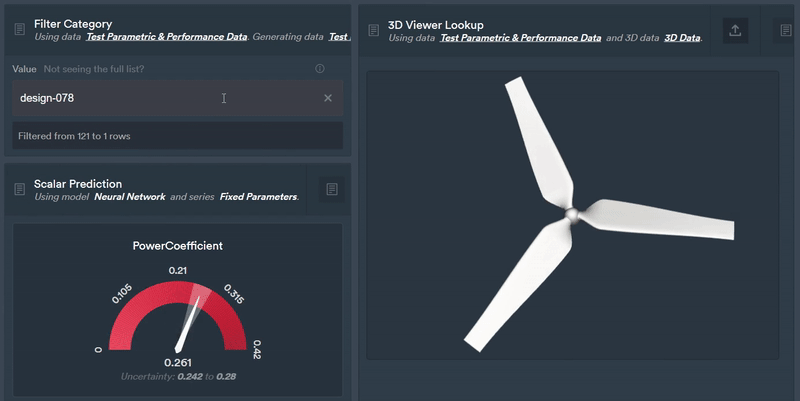
Figure 7: Using the Monolith AI platform we can easily select a design and instantly view downstream model predictions from our latent parameterisation.
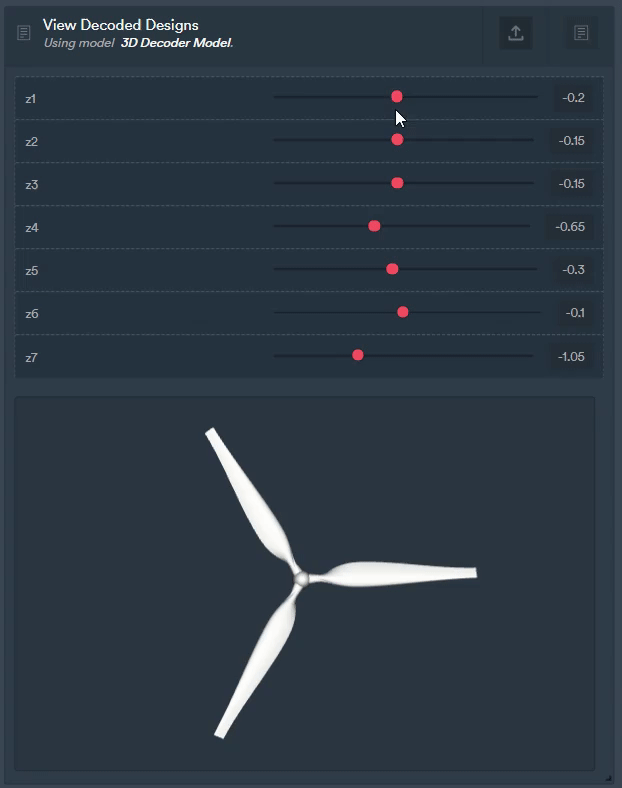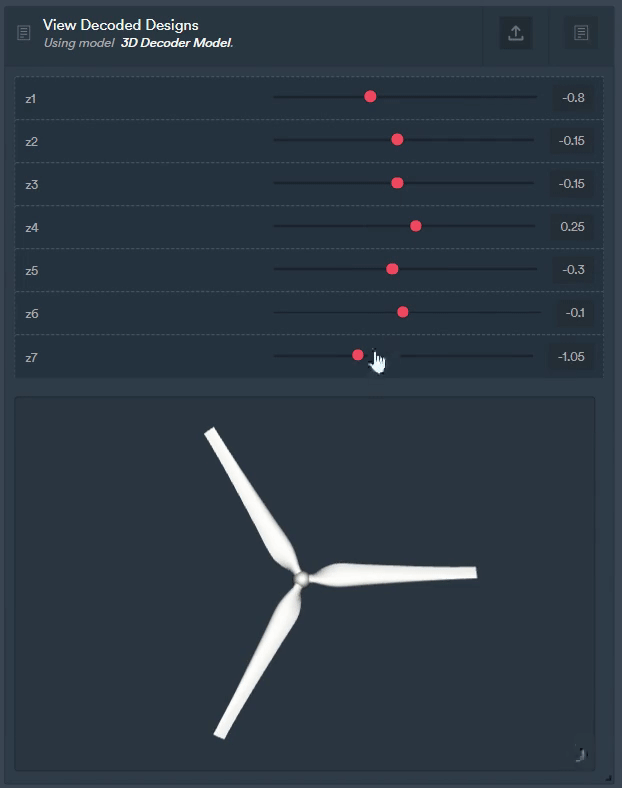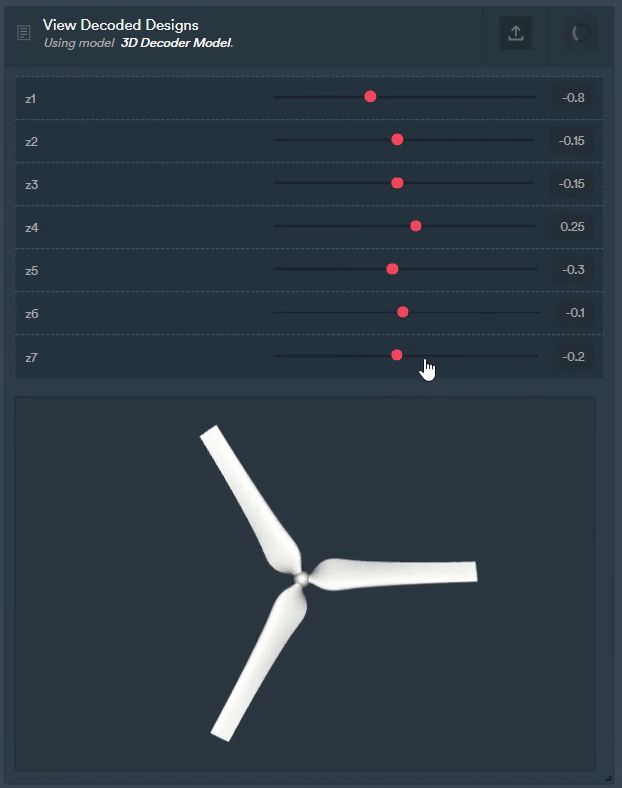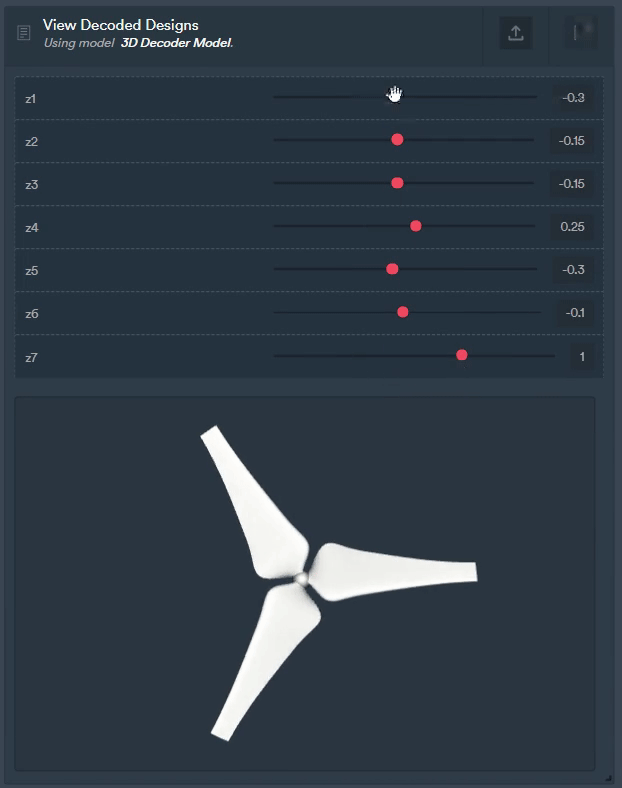
Figure 8: The same autoencoder can be used for other purposes too like generating completely new geometries.
Deep learning and transfer learning conclusion
In this article, I introduced the concepts of transfer learning and how autoencoders can provide a generic representation of 3D data that can serve multiple purposes without needing to be retrained on each use case.
Whilst transfer learning for 3D data is still very much an open research field, autoencoders are a powerful way to learn from complex 3D data and overcome the smaller data challenges often encountered within product development cycles.