


Guide to data preprocessing in machine learning
Turning engineering data into actionable insights.
In battery projects we have worked on at Monolith, tabular data is often made up of different test input conditions (such as voltages, currents, etc), operating conditions (temperature, driving style, etc), and outputs (or test results) organised in a table of rows and columns.
With these structured test results, engineers can train Machine Learning (ML) models to gain valuable insights into the performance of their product designs to make predictions, optimise testing plans, and improve product design.
For any ML model process, the model's quality depends on the quality of the data used to train it. As we delve into tabular data, addressing the challenges associated with data preparation becomes important.
A key aspect to note is that while most platforms and open-source tools support multiple file formats, adherence to a specific structure and focus on engineering data is essential for successful model generation and adoption in the engineering industry, particularly the R&D sector.
3 steps to model training for data preprocessing in machine learning
In this blog post, we’ll cover the 3 basic steps to prepare your raw data for modelling:
-
Data structure – recommendations for organising your test results into a tabular format
-
Data exploration – methods for understanding your data and finding issues, such as outliers, gaps, or duplicates
-
Data preparation – tools for cleaning, fixing, and transforming your data to address issues and prepare it for model training

The challenge: data format
Tabular data, or rows and columns of test results, are most often stored in databases or comma-delimited text files (.CSV or spreadsheet files).
As we share common issues and best practices for raw data organisation and preparation, the guidelines apply equally to data files or data structures stored in a database.
Interestingly, the nuances of machine learning tabular guidelines may not always align with conventional engineering tabular practices.
Time series data and spreadsheet data are distinct concepts, although time series data can be organised and stored within a spreadsheet.
Some of the common mistakes for time series are given in Figure 1.
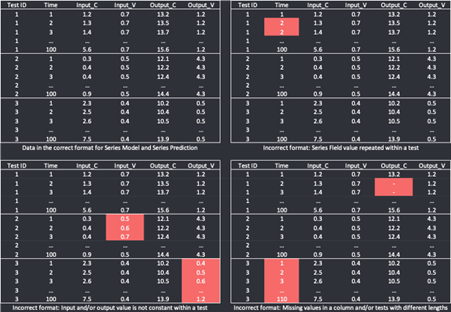
Fig.1: Time series examples with data in the correct format for time series model and prediction (top left), and faulty example with issue highlighted in red. (Top right) Should increase time and not keep time constant. (Bottom left) Need to keep Input_V value constant, same for Output_V. (Bottom right - time column) Test 3 had 110 time steps, while the other tests only had 100. (Bottom right - Output C): Missing data values
Data structure guidelines
You can follow simple guidelines to ensure your test data is organised and ready for AI modelling. These requirements encompass general guidelines applicable to all data types and specific considerations for spreadsheet files.
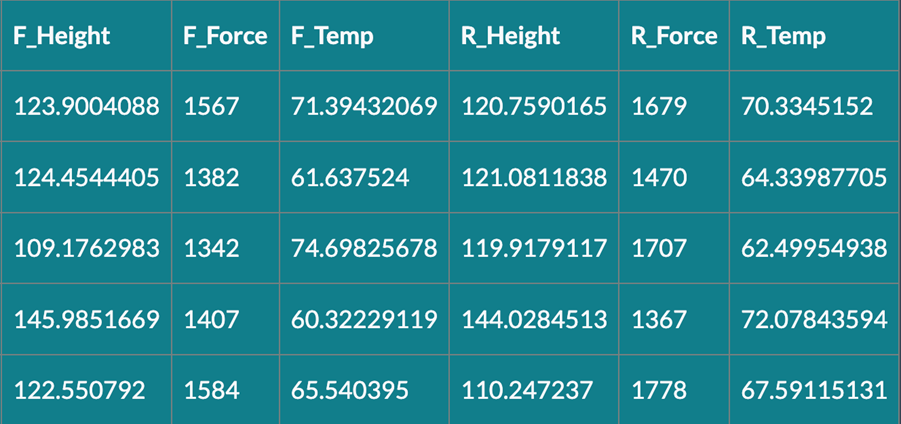
The example above follows a correct structure of how tabular data should be uploaded for accurate ML models.
General guidelines:
- Each column should house only one variable, promoting clarity and precision.
- Rows should serve as indices for experiments or sequence stamps, such as test numbers, simulation IDs, or time stamps.
- Every column in the dataset should be classified according to its data type (e.g., string, float), discouraging the inclusion of multiple data types within a single column.
- Consistency is paramount when dealing with categorical data (i.e., strings), as the platform assimilates spaces and is case-sensitive. For instance, "MonolithAI," "Monolith AI," and "Monolith ai" are treated as distinct categories.
- Column labels should be confined to a single row; nested categorisation is discouraged.
Excel file guidelines:
- Merged cells in the uploaded sheet should be avoided to maintain data integrity.
- Font colour, size, and type will not impact the data, ensuring that the substance of the information remains unaffected.
- If an Excel file contains multiple sheets, only the first sheet will be uploaded, streamlining the process.
- Uploaded files should exclude any images, focusing solely on the tabular data.

Data exploration
The primary objectives during this stage are to confirm data accuracy, identify trends, and validate expectations. The key to an accurate machine learning model is training it with clean, complete data that covers relevant conditions. You must apply your understanding of the design and performance requirements to determine if your data is correct and if you have the right data.
With a large spreadsheet file or database of tabular data, it can be challenging to know if you have gaps or discontinuities in your data. Using simple visualisation tools, you can quickly inspect and find issues that could impact the quality of your model.
For example:
- Does your data effectively cover the design space?
- Do you have the correct set of parameters captured in your inputs, and does your test plan cover an appropriate range of those values to cover the performance areas of interest?
- Does your test data have the resolution needed (have you sampled values at the right time intervals for visibility into the most important details)?
- Are there important limits or boundary conditions that you must test for to ensure proper operation?
- Does your data have outliers that could suggest errors or system issues?
- Do you have missing data?
Data exploration aims to show meaningful relationships within the dataset, laying a solid foundation for informed decision-making and effective model development. Machine learning models are a great way to understand, predict, and optimise your designs fully, but only if they are trained with data that covers the right conditions.
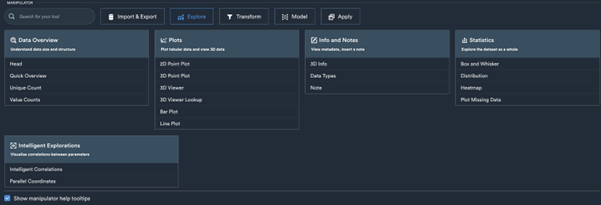
Fig.2: Monolith's data exploration feature empowers users to delve into the intricate details of their datasets, validating trends, checking for outliers, and ensuring data integrity for informed decision-making in machine learning projects.
Data preparation
In the subsequent step of the ML pipeline, data pre-processing takes centre stage, aiming to optimise the dataset for effective model development. The objectives of pre-processing are diverse and can vary based on the initial state of the dataset.
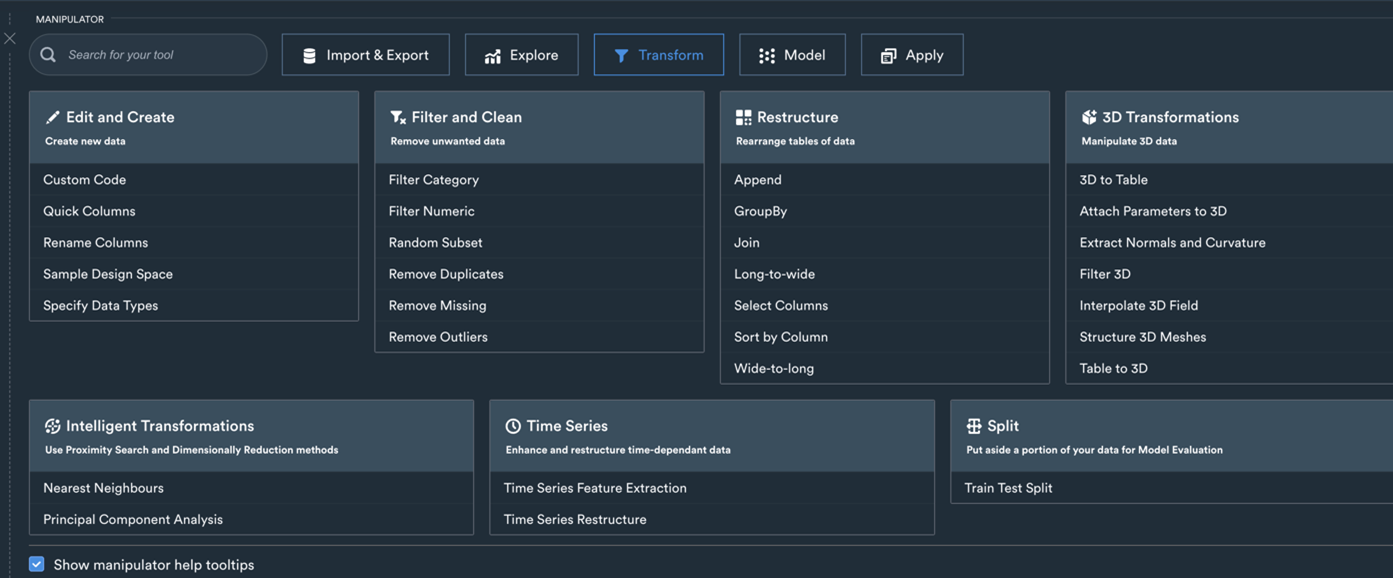
Fig.3: An excerpt from some of the Transform tools Monolith's solution offers to engineers.
First and foremost, the focus is on data cleaning, such as removing outliers, duplicates, and missing values found during the data exploration stage. The process ensures that the model is not adversely influenced by irregularities or biased information.
Bringing the data into the required shape is the next facet of pre-processing, including adding or calculating additional columns, converting dimensions, changing dataset structures, and selectively removing unnecessary columns to enhance efficiency.
For example, suppose you have a column representing velocity at different times. In that case, you might learn more about your design if you converted velocity to acceleration by creating a new column and applying a derivative function.
Or, you might have two columns representing the dimension of a design component, and a more interesting input might be the area, which you could create as a new column.
Monolith has tools for generating new data columns based on calculations like these.
Furthermore, data splitting into separate datasets may be necessary based on physical regimes or geometrical families, recognising that different subsets may require distinct modelling approaches.
In addition to adding or splitting columns, you may need to join data by combining values through horizontal or vertical concatenation.
The pre-processing stage lays the groundwork for a refined and well-structured dataset. It costs around 60-70% of the time for every project starting from scratch and is very important when aiming for robust and accurate machine learning model development.
Conclusion: data preprocessing in machine learning
Before taking advantage of AI, you or your team must clean and prepare your data systematically.
Based on our experience with many engineering projects, Monolith has developed tools and guidelines for data structure, exploration, and preparation to clean and transform your datasets.
By adhering to these steps, one can ensure the dataset's quality, optimise features for model learning, and create models well-suited for your specific needs.
If you want to accelerate product validation with AI-guided testing in the battery segment, for example, do not hesitate to reach out and book a demo with our team of experts.