


Physics-based Models or Data-driven Models – Which One To Choose?
Should we rely on physics-based models or data-driven ones? This question represents a fundamental choice facing today's R&D leadership—one that deserves careful consideration as engineering teams increasingly find themselves at the limits of traditional modelling approaches.
Traditionalists often favour physics-based models, which describe natural phenomena through established mathematics and computational science. They point to the foundational equations that have advanced science and engineering for centuries—from Newton's laws of motion to Maxwell's equations—as evidence of this approach's enduring value and rigour.
By contrast, data-driven methods, underpinned by artificial intelligence (AI) and machine learning (ML), represent a more recent addition to our analytical toolkit. Much like computational fluid dynamics (CFD) when it first emerged decades ago, these approaches initially met resistance but have since demonstrated remarkable capability in solving previously intractable problems.
Ultimately, developing more accurate and efficient predictive models requires a thoughtful integration—leveraging established physical principles while harnessing data to illuminate complex phenomena that elude purely theoretical description.
Figure 1: The Jota Sport team replaced time and cost-intensive testing with data-driven self-learning models to measure and monitor tyre degradation with training data, one of many intractable problems that were solved by their engineers.

Determining where physics ends and where data should begin remains a significant challenge. The question has taken on newfound urgency as R&D cycles compress and system complexity escalates—particularly in battery technology, where electrochemical processes across multiple scales often defy clean mathematical description yet demand precise prediction.
Today's competitive pressures require solutions that are simultaneously more innovative and reliable while meeting increasingly aggressive timelines. The question is no longer whether to use physics or data, but rather how to strategically integrate them for each specific engineering challenge.
Machine Scientists: Uncovering the Laws of Physics from Raw Data
According to an article in Quanta Magazine, the scientists Roger Guimerà and Marta Sales-Pardo were able to develop an equation to predict when a cell would divide. However, this was not achieved through traditional scientific means. Instead, it resulted from a machine learning algorithm that was trained to develop governing equations based on laboratory test data and field data. When used, the equation delivered excellent predictions of when a cell would divide—they just didn’t know how this specific equation had come about. This leads to the question: Just because we don’t know how an equation that works well came about, should this be grounds to disregard it?
In practice, pragmatic considerations often supersede theoretical purity. R&D leaders facing competitive pressures and strict deadlines cannot afford philosophical debates when viable solutions are at hand. What matters ultimately is predictive accuracy, reliability, and speed, regardless of whether the underlying model derives from first principles or sophisticated data analysis.
This paradigm shift is further enabled by the wealth of historical test data accumulated by most engineering organisations. Years of development cycles have generated valuable information that, when properly leveraged through AI and ML techniques, can unlock insights into previously intractable problems—from complex material degradation mechanisms to multi-parameter optimisation challenges that conventional physics-based simulations struggle to address efficiently.
When Does a Problem Become Intractable?
Engineering problems become intractable when they exceed practical computational limits—not merely theoretical ones. This distinction is crucial for decision-makers weighing investment in simulation infrastructure against project deliverables.
The classic example is fluid dynamics, where fully-resolved simulations of turbulent flows around complex geometries remain prohibitively expensive despite significant computing advances.
Consider a typical automotive aerodynamics case: while the Navier-Stokes equations theoretically describe all fluid behaviour, direct numerical simulation (DNS) of airflow around a complete vehicle would require billions of cells and months of computing time on high-performance clusters. Engineers must instead rely on approximations like RANS (Reynolds-Averaged Navier-Stokes) models, which introduce their own uncertainties through necessary simplifications of turbulence physics.
This is precisely where data-driven methods demonstrate their value. By training on high-fidelity simulations of critical components and correlating with wind tunnel measurements, machine learning models can predict aerodynamic performance across design variations with remarkable accuracy—often in minutes rather than days.
The computational efficiency translates directly to business value: more design iterations, faster time-to-market, and ultimately better-performing products. For engineering leaders, recognising this inflection point between physics-based and data-augmented approaches has become a strategic competency.
 Figure 2: The core of the Kautex engineers’ challenge was to reliably understand the relationship between the properties of the fuel tank, the test parameters, and the resulting sloshing noise – an intractable physics procedure typically requiring multiple physical tests and costly CFD simulations with prototype tank shapes filled at differing levels.
Figure 2: The core of the Kautex engineers’ challenge was to reliably understand the relationship between the properties of the fuel tank, the test parameters, and the resulting sloshing noise – an intractable physics procedure typically requiring multiple physical tests and costly CFD simulations with prototype tank shapes filled at differing levels.
Solving Intractable Physics: How Kautex Predicts Sloshing Noise with Self-Learning Models
Kautex Textron, a global leader in automotive fuel systems, faced a classic example of intractable physics—predicting fuel sloshing noise inside complex tank geometries. This challenge highlights where traditional simulation methods fail: a highly nonlinear phenomenon involving fluid-structure interaction, acoustic resonance, and chaotic behaviour that CFD struggles to model accurately.
The core challenge for Kautex Textron engineers was to reliably understand the relationship between fuel tank properties, test parameters, and the resulting sloshing noise—a complex, intractable physics problem that typically demands numerous physical tests using prototype tanks at varying fill levels.
Using Monolith AI software, they developed data-driven models of sloshing behaviour that matched physical test results within a 10% margin of error in 94% of simulations.
“With Monolith’s machine learning method, we not only solved the challenge, we also reduced design iteration times and prototyping and testing costs. The software reduces design analysis time from days to minutes with improved accuracy. We are thrilled with the results, and we are confident we have found a way to improve future design solutions.”
Dr. Bernhardt Lüddecke, Global Director of Validation, Kautex-Textron

AI To Speed Up Product Development Processes: Data-Driven Model
Understanding when a problem becomes intractable is one thing—solving it is another. To illustrate how data-driven approaches deliver tangible business value in practice, let's examine several real-world applications where Monolith's technology has overcome limitations in traditional physics-based modelling.
One application where the classical physics-based approach has run out of steam is in the field of gas and water metres. Flow meters are an essential part of energy provision for commercial and consumer buildings, ensuring that gas delivery is accurately measured and billed. However, one manufacturer had trouble with their CFD models for building meters with enough precision to meet government regulations.
Despite significant investment in simulation, it had proven impossible to find the optimal configuration for the meters. As a result, each meter had to be tested under a wide variety of conditions to calibrate it—a lengthy and costly task. Even a heuristic algorithm provided by an electronics supplier had failed to resolve the issue. The entire programme’s time-to-market goals were significantly at risk.
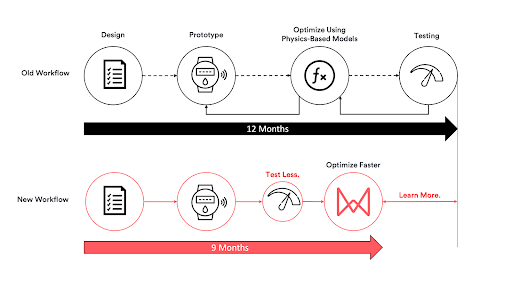 Figure 3: The idealised workflow for a well-understood (linear) problem where time-to-market and testing are minimised by solving known equations which depend on a physics-based model.
Figure 3: The idealised workflow for a well-understood (linear) problem where time-to-market and testing are minimised by solving known equations which depend on a physics-based model.
The silver lining to this challenge came in the form of data—in particular test data—in combination with machine learning algorithms to calibrate the meters.
By uploading, transforming, and feeding the data into the Monolith platform, the ability of our self-learning models to model exceptionally complex non-linear systems delivered a result that reduced testing and accelerated time-to-market while also fulfilling legal requirements.
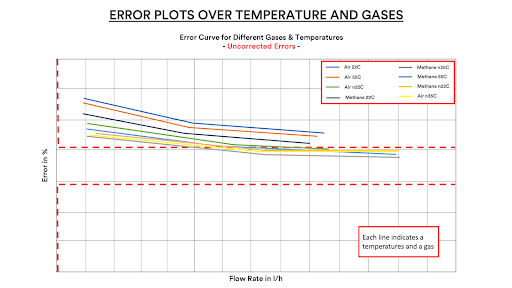
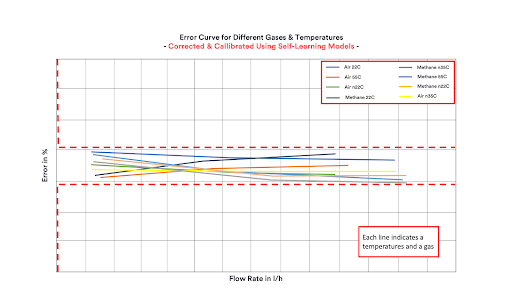
Figure 4 & 5: Using self-learning data-driven models, they not only fulfilled the requirements but also achieved results much faster compared to running time-intensive, tedious, and repetitive test campaigns. At the beginning of each calibration process, the accuracy of the gas meters tends to be outside the legal requirements (top image). Engineers need to calibrate the meters to fall into the red boundaries (lower image). Courtesy: Honeywell.
The key to this impressive feat lies in the challenges of solving the polynomial equations required for the CFD model. These often fail in high-dimensional, volatile systems and don’t tend to improve by providing them with more data and are often based on complex assumptions that might not represent the real-world environment.
After all, engineers only have to fine-tune a model using the available tools. On the other hand, the neural networks of a self-learning algorithm become more accurate as more data is applied, even in highly stochastic and volatile systems.

Engineers Use Existing Vehicle Data to Build Self-Learning Models
Crash testing is a major expense, and leg injuries are typically assessed using the tibia index. Vehicle manufacturers must ensure this value remains within regulatory limits across a range of crash scenarios. However, the results collected for specific vehicle models are often archived and seldom revisited.
This is common across many engineering domains despite product development being inherently iterative, where each new design builds on past solutions. Collaborating with a leading automotive OEM, a self-learning model could be developed using historical tibia index crash data.
This enabled design changes to be explored that traditional simulations alone couldn’t capture, due to the intractable nature of the underlying physics. Not only did this accelerate the optimisation of the final design, but it also ensured the data remained valuable, ready to inform future models and benefit future generations of engineers.

Conclusion: Physics-Based Model or Data-Driven Model
Machine learning is following the adoption path that CFD once traveled—from novel technique to essential engineering tool. The critical question for today's R&D leaders is not which approach is superior, but rather which is appropriate for specific challenges.
Data-driven methods excel where traditional physics-based models struggle: complex, multi-dimensional problems that defy accurate simulation through conventional means. What makes this opportunity particularly compelling is that most engineering organisations already possess the necessary foundation—years of accumulated test data from previous development campaigns.
The business case is compelling: physics-based models remain invaluable for well-understood phenomena, while data-driven approaches offer faster insights for complex systems under compressed development timelines. In some cases, as demonstrated by Monolith's work with partners across industries, these approaches have proven to be the only viable solution to otherwise intractable problems.
Engineering organisations that thrive will be those that develop both the judgment to select the right tool for each challenge and the capability to integrate physics-based and data-driven approaches effectively.