


According to McKinsey, “over the next two decades, artificial intelligence (AI) will transform most aspects of the auto-manufacturing process. In particular, advances in AI will give machines the ability to learn from past experiences how to improve future performance."
The main challenges engineering organisations face with regard to the adoption of AI and/or the use of machine learning in automotive industries, is that they are hampered by tools and processes that require repetitive, time-intensive, and costly testing.
Automotive industry experts and their respective companies feel as though they are unable to learn from previous data (explicit knowledge), and experiences (implicit knowledge), lack the collaboration capabilities enabling agile R&D, and are most often tied to desktop-based workflows.
"Monolith understood what it means to work with genuine engineering problems in artificial intelligence: the needed flexibility and knowledge."
Joachim GUILIE
Curing performance expert at Michelin
These are major drawbacks for automotive industry engineering teams to learn from historical data to train self-learning models in a promising way to accelerate time-to-market and cut development times by up to 50%.
Instead of hiring more Python coders or data scientists and waiting months for meaningful insights, Monolith magnifies automotive industry engineers’ expertise and test data to develop to predict the outcome of new unseen product scenarios, which dramatically accelerates design cycles and allows for delivery of better quality products in half the time.

AI adoption: reduce tests & simulations to learn more from your automotive data
Automotive industry engineering organisations that are invested in digital transformation, are on a journey to increase agility, and improve compliance and quality of their products by using data-driven technologies. They realise that the repetitive nature of their product development workflows lends itself very well to an AI solution that learns from past experiences to predict the outcome of new ones.
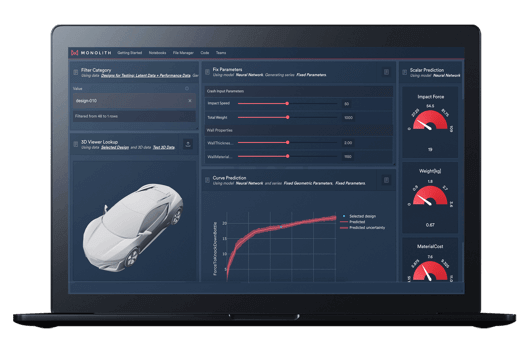
Figure 1: Using Monolith, BMW Group engineers built self-learning models using the wealth of their existing crash data and were able to accurately predict the force on the tibia for a range of different crash types without doing physical crashes.
Traditionally, the automotive industry has relied on empirical and numerical models to tackle intractable physics problems as well as repetitive physical tests to design and manufacture components that fulfill customer requirements. The engineering disciplines or areas of focus can be aerodynamic performance, the structural integrity of a system, weight reduction, Noise Vibration & Harshness (NVH), manufacturability, and more.
Let’s take the specific example of a rim design. Engineers know that the wheel design and type of tyre impact the drag and ultimately the efficiency of the vehicle. Finding the optimal wheel and tyre configuration is key to meeting performance and efficiency targets.
The traditional approach for engineers is to build physics models to predict the optimal car-wheel combination to find a rim design that achieves the desired vehicle optimisation target. This is extremely difficult, if not impossible, and relies on expensive, time-intensive testing under mounting time-to-market and quality pressure.
On top of that, aerodynamics engineers within the automobile industry will do their best in the wind tunnel to get the most insights they can by testing 50 different wheels on multiple cars. Yet, testing these cars and their respective vehicle features in wind tunnels can cost up to 10s of thousands of euros per hour for every single vehicle.
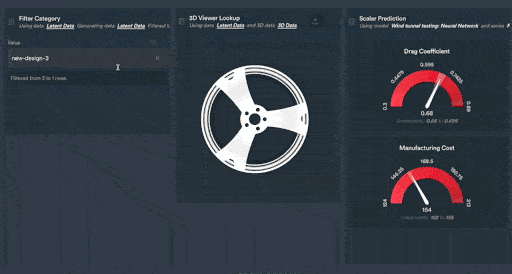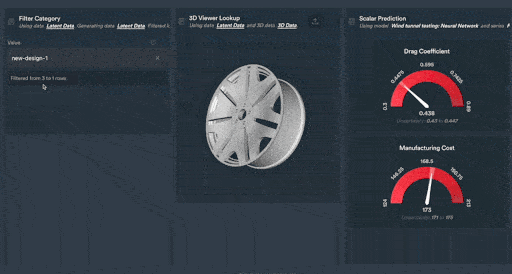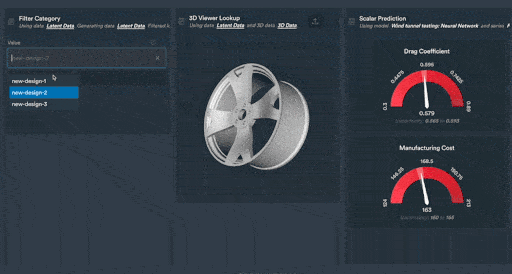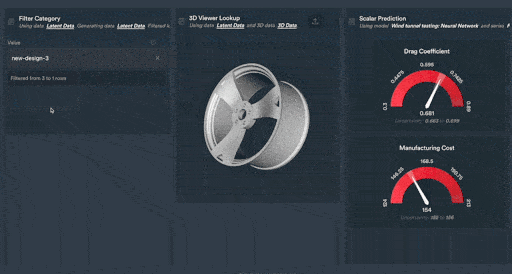
Figure 2: Monolith’s interactive shareable dashboards allow your team of engineers to explore vehicle data in a clear and configurable way. In this example, new car rim designs are explored using Monolith’s patent-pending Autoencoder technology.
The expertise and the vehicle data produced from these wind tunnel tests represent a goldmine of historic knowledge which can be leveraged by self-learning models in various ways.
By adopting self-learning models into their product development processes, automotive companies can build machine-learning models which are capable of predicting the outcome of such tests.
By doing this, automotive engineers can avoid running an extensive Design of Experiments (DoE) as it relies heavily on statistics and the number of experiments required using the basic DoE methodology increases on the order 2x, where x is the number of input variables requiring 128 runs for 7 variables alone. For automotive manufacturers and engineers alike, this is an almost unfeasible endeavour in the modern age when coupled with dealing with expensive physical prototyping.
One of the major pain points in the automotive industry is to find methods to accelerate product development processes as they often deal with the competitive nature of supplying products and services to OEMs. The so-called Request for Quotation (RfQ) process is a particularly competitive segment in the process, in which the company needs to provide guarantees of manufacturability and performance in a highly timely manner.
Once a design has been assigned to them for manufacture, in-depth development begins, and it is critical to make efficient use of vast amounts of resources in order to remain competitive.
It is therefore essential to extract value with AI from historic designs and test data to enable engineering organisations to drastically reduce the number of tests to carry out, assess and/or optimise product performance. But who is best positioned in the company to do so?
Automotive engineers at the centre of the digital edge
The emergence of AI is making companies increasingly eager to transform their business towards deriving insight from data-driven methods for decision-making. However, for large traditional companies, this is a complex challenge: their data is often static, and their analytics tools can’t handle vast amounts of data and don’t have AI capabilities built in.
To address this challenge, many companies turn to data scientists with hands-on AI experience as the people who can help make this technology change happen for them. However, relying exclusively on data scientists is a major risk, especially for automotive engineering organisations.
As well as being scarce and expensive, they often lack the context and intuitions which are needed to understand and handle engineering data. Automotive industry companies who realise this challenge look to engage automotive engineers themselves to gain a digital edge with AI through employing machine learning algorithms.
Many automotive engineers are deeply embedded in the business and understand better than anyone else the complex physical systems on which they work daily. Additionally, an automotive engineer understands the kind of insights that are needed to drive positive change for their team and their organisation.
“For the development of a new gas meter, our engineering team used computational fluid dynamics (CFD) to better understand the gas meter's flow dynamics. However, CFD models turned out to be not accurate enough to capture the complexity of the flow for varying temperature conditions and types of gases. Using the Monolith AI platform, we were able to import our rich test stand data and apply machine learning models to conclude different development options much faster. Monolith allowed us to understand and optimise the gas meter's behaviour for all operating conditions and optimise meter accuracy under extreme conditions. This allowed us to build a superior product in a much shorter amount of time."

Dr. Bas Kastelein
Senior Director of Product Innovation at Honeywell
Monolith’s no-code solution aims to democratise AI, by empowering engineers to self-serve in building AI solutions for their engineering problems. In our experience, engineering expertise coupled with easy access to complex AI tools is a winning recipe that drives digital transformation for engineering organisations.
But how exactly might an engineer build and deploy AI models, for intractable automotive industry engineering use cases?
Encoding complex 3D data in the automotive engineering industry
Self-learning models are mathematical algorithms that train models using data in order to make predictions without being explicitly programmed to do so. The data used to train these models could be contained in a simple spreadsheet, with each column corresponding to an input or output variable and each row corresponding to an observation.
In engineering use cases, the input parameters might be geometric parameters, boundary conditions, operating conditions, or environmental conditions. Output parameters might be the results of a numerical simulation or of a physical test where the Monolith experts see a greater ROI in the latter one. Trained machine learning models understand the correlation between the inputs and the outputs and are therefore capable of predicting the performance or quality of a new design tested under new conditions.
However, in many cases, it is impossible to fully describe a design’s geometry with a straightforward set of known numerical parameters or measurements. For rim designs, the creative freedom in the design process means that there is an unlimited amount of variation which the geometry could adopt - an intractable problem. Indeed, 3D wheel designs represent highly complex aesthetics and it has been difficult to develop methods of deriving quantitative ways of comparing this kind of 3D data in order to feed it into self-learning models, up until now.
Automatic parameterisation for automotive engineering
Monolith has developed patent-pending 3D deep learning technology capable of automatically parameterising a dataset of 3D CAD designs. These algorithms can scan 3D CAD files to extract the distinct geometry feature which characterise each design.
This automatic parameterisation has two major benefits:
- To encode new designs into a set of numerical parameters, in order to predict their performance.
- To generate new, performance-optimised designs which satisfy target goals and constraints.
The starting point is a dataset of 3D CAD files. These designs have complex aesthetic differences between them which are impossible to quantify manually.

Figure 3: 3D Autoencoder designs trained by Monolith’s deep learning algorithm.
Deep learning algorithms enable these complex designs to be parameterised. A new 3D design created by a designer or engineer that has been parameterised can be quantitatively compared to other designs in the dataset of historic 3D data. These learned dependencies of the algorithm can then be used as inputs to more conventional self-learning models such as Neural Networks, which predict performance quantities of interest.
The ultimate aim is to enable users to make instant predictions for the outcome of simulations or physical tests, for new 3D designs.
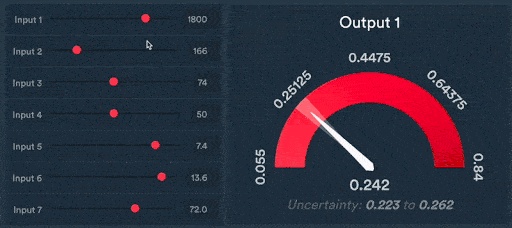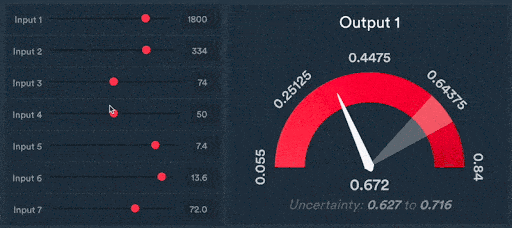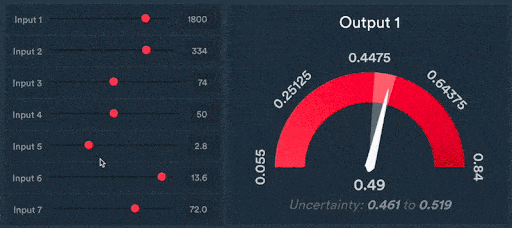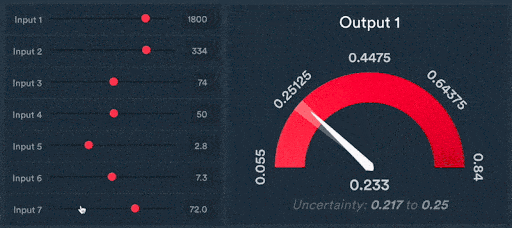
Figure 4: Scalar predictions of new wheel designs
The ability to make predictions for the outcome of tests or simulations by presenting complex 3D CAD data in this way is a game changer for engineering organisations. It allows design and engineering teams to iterate much faster by reducing the number of simulations or tests needed to be carried out to develop high-quality designs.
Augmenting automotive engineering R&D processes with artificial intelligence
There are several key and reoccurring factors as to why engineers use Monolith to make their traditional engineering workflows more efficient:
- Knowledge is being retained
The results of tests or simulations carried out during development are usually not captured, meaning very little knowledge is being retained for future generations of designs, developed by future generations of engineers.
- It involves minimal effort
Engineers are able to create accurate, self-learning models to quickly understand and instantly predict the performance of complex systems. Because of the iterative nature of traditional engineering workflows, a lot of an engineer’s time is spent setting up repetitive, cost-intensive, and tedious empirical testing, analysing, and preparing reports for one result at a time. Innovative engineering teams are now able to use reliable real-time predictions by Monolith’s self-learning AI models to stay in the fast lane of highly competitive engineering domains.
- Engineers do not need to start from scratch
For example, an engineering team that has worked on refining a design for the last months around a narrow set of goals and constraints from other departments. What if these requirements suddenly change? Engineers will still encounter this issue with the use of traditional design exploration tools since the design requirements for optimisation campaigns need to be defined upfront.
- No iterative guessing games
How should engineering teams change a design to improve its performance? How can a team find an optimum when considering multiple goals and strict design constraints? These are the questions that engineers usually are failing to quantify and answer.
Monolith enables engineering domain experts to use AI to make the product development process faster and smarter while fulfilling multiple optimisation targets. On top of that, self-learning models become better over time. The more data you acquire over time, the better your system becomes which is a big advantage compared to heuristic approaches in physics-based systems.
The result: higher ROI, better quality products, and product performance in half the time.
Combining automotive sector learnings from different stages of the vehicle product development process
For a plethora of automotive organisations Monolith is working with, it was quite clear that there’s no more time to waste. The development of a new product involves complex sets of performance and quality requirements, each indicated by their own simulation or physical test. The aim of engineering teams is to find the right balance between different performance parameters, manufacturing costs, and durability, or between aerodynamics and aesthetics.
“Monolith has already radically changed how we operate. Their software streamlines how our car and simulation data is validated.”

Tomoki Takahashi
Technical Director at Jota Sport
Avoid collisions and improve automotive engineering with artificial intelligence (AI) solutions
Working with the world's top automotive engineering companies, they can clearly see the full benefit when using AI models capable of predicting multiple performance metrics to help in decision-making. Indeed, by gathering historic data from multiple engineering teams, users can paint a holistic picture of the performance of new designs which helps them understand the trade-off which may exist and make better-informed decisions.
In particular, the ability to forecast late-stage performance in the early stages of a product development process can help engineering teams prioritise design and engineering effort in areas of their product that may have otherwise required costly U-turns in the development.
Additionally, this insight benefits supply chain management, manufacturing, production, maintenance costs, and even informs new product designs in the coming decade and beyond.
How to get started with Monolith AI and machine learning
To enable building this cross-functional AI solution, Monolith offers users the ability to collaborate by sharing data, models, data processing pipelines, and dashboards on the cloud.
The ease of installation and ease of use of the product is a strong enabler for effective collaboration – and a prerequisite to building a network of self-learning models that touch upon all aspects of the development of new designs.