


What engineering leaders need to know about big data storage and employing self-learning models
Engineering data has been hoarded on hard drives and desktops for decades. What’s changed is the perception of this data - that the information belongs to the collective company as opposed to the individual. Collating this information across different individuals and across different silos, transforms it into a powerful resource for these companies.
Plenty of businesses have historic data sitting dormant in digital storage or data warehouses. This data can include raw data, unstructured data, structured data, process data, query data, source data, and the list goes on.
However, until recently, most companies and data engineers alike didn't realize the business value of this data collected.
Today, it is much more common to see data as one of the most valuable resources of a company, and a major part of the design and testing process of any new product.

Most engineering companies (and even data scientists) are still learning and understanding how to collect data in the right way, not knowing that their existing data warehouses and data lakes are potentially worth billions.
Moreover, these data lakes can be leveraged through the adoption of AI and the use of machine learning (ML) self-learning models which feed on that transformed data to increase business intelligence and inform business decisions around product design.
Let's dive into data lakes!
What is a data lake?
Many engineers ask the same question, 'what is a data lake?'. A data lake is a centralised repository that allows for data storage of all structured and unstructured engineering data at any scale (from big data to small datasets).
You can store your data as-is in data lakes from multiple sources, without having to first structure the data, and later capitalise on this data access to run self-learning models to ultimately improve business intelligence leading to better (and faster) design decisions.
An organisation can either build a data lake on-premise or build a cloud-based data lake solution to store data, on which they can run different types of self-learning models using their respective data lakes.

Avoid creating a data swamp with effective data management for storing data
However, poor data management will degrade those lakes into data swamps.
Data swamps make collected data sets less useful at a later data ingestion stage to use as input data sources for machine learning and self-learning models.
While a data lake can store any kind of data, it is not ideal to store everything in a data lake with the hope that it will provide immediate use in its native format.
The different types of data and states of data quality stored in a respective data lake define the output data performance.
Therefore, some data lakes may need more data cleaning before employing machine learning solutions; especially if the centralised repository has large volumes of data from multiple sources.
In an ideal scenario, a data lake should store accurate and useful data, to then be used as input for self-learning models requiring minimal effort for engineering teams, ultimately allowing for the output data to be reliable to inform accurate predictions and increase overall business intelligence.
The last hurdle for maintaining and utilising a data lake effectively is ensuring clear communication between all involved stakeholders; from data scientists and engineers, to all involved team members.
A data lake should not look like an opaque storage, and businesses must maintain company-wide awareness of how and why to use the data lake.

Sharing knowledge and insights between shareholders using Monolith dashboards is key for effective decision-making and faster time-to-market.
Monolith’s intuitive AI platform is compatible with data engineers’ most frequently used data types and formats across virtually all industries. This spans from:
- Tabular test data such as .csv .xls .txt .dat and .parquet
- 3D Data such as .vtk or .stl files with which you can also convert CAD files such as .step & .iges files to meshes
- Hierarchical Data Format (HDF) data
- Tabular data that can be loaded from your external SQL database by running PostgreSQL or MySQL queries
- MATLAB files with the extension .mat
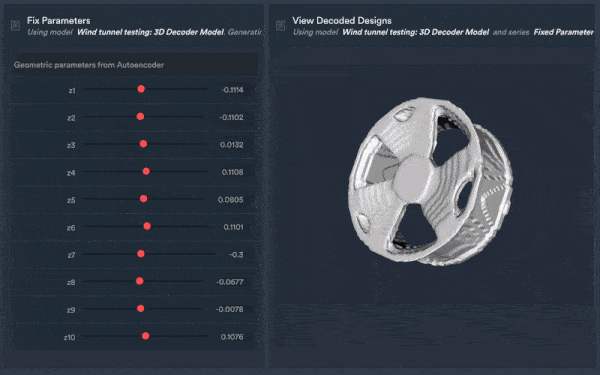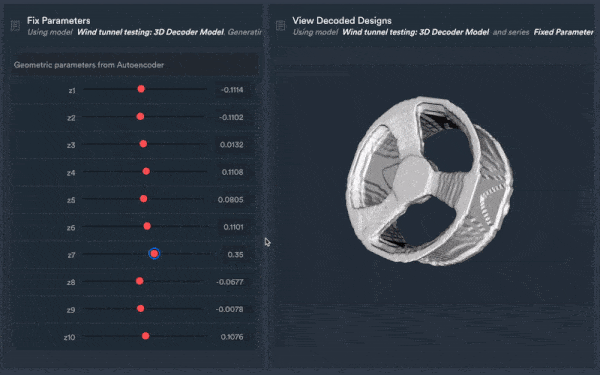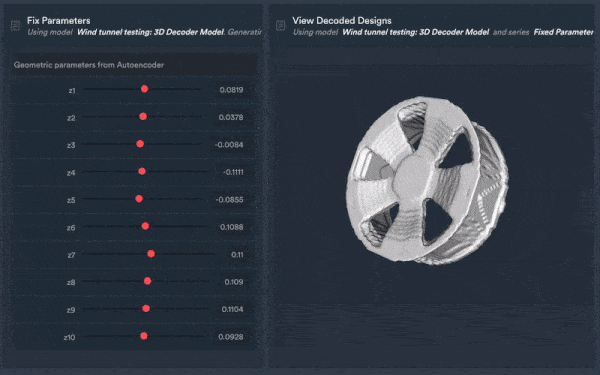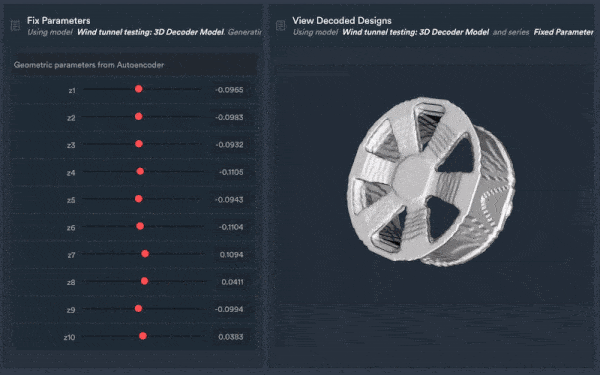
Data engineering example of the Monolith algorithm learning from historic 3D data, extracting its DNA, and generating new CAD data fulfilling engineers’ optimisation targets.
This allows engineering teams to dive into their respective data lake, and unearth new higher-order relationships from their existing engineering data.
Additionally, teams can use previous CAD designs to build AI models and predict future product designs and outcomes or meet new needs such as sustainability, cost or other relevant performance metrics such as drag such as from wind tunnel tests of a rim from its CAD design — resulting in faster and more accurate predictions compared to physical tests while reducing test times by ~70%.
Monolith’s data import modules allow teams to gain insights into their work that no other data modeling solution is able to deliver.
AI that's easy to use for domain experts for data engineering. Built by engineers, for engineers.
The benefits of creating a digital replica of a product using real-time data, and applying self-learning models to it are significant.
It is now possible to incorporate learnings (utilising your data lake or data warehouse) from previous designs to create better, more efficient products for the future under mounting time-to-market pressure.
“… VW Group has about 10,000 engineers, but only a few hundred programmers. You need people…, who can work in cloud computing and who are proficient with artificial intelligence”
Martin Hofmann, Chief Information Officer, VW Group
According to Vincent Higgins, global director at tech futurist company Honeywell, “The most common mistake people make is that they hire data scientists without bringing the subject matter experts along. Successful application of AI is a marriage of data and expertise right down to the granular level.”
With the right R&D processes in place, businesses can bring together their existing data lakes (explicit data) with the knowledge and complex physical behaviour of seasoned engineers (implicit data). This, in turn, will leverage all of their capabilities across data science and data engineering.
By using Monolith’s self-learning capabilities to help extract knowledge from data, engineers can access this knowledge base and instantly incorporate it into their work.
In turn, Monolith ensures that institutional knowledge is leveraged, shared, and documented for generations to come.
Adopting self-learning models for data engineering
There are several key and reoccurring factors as to why engineers use Monolith to make their traditional data engineering workflows more efficient:
- Knowledge is being retained. The results of tests or simulations carried out during development are usually not captured, meaning very little knowledge is being retained for future generations of designs, developed by future generations of engineers.
- It involves minimal effort. Engineers are able to create accurate, self-learning models to quickly understand and instantly predict the performance of complex systems. Because of the iterative nature of traditional engineering workflows, a lot of an engineer’s time is spent setting up repetitive, cost-intensive, and tedious empirical testing, analysing, and preparing reports for one result at a time. Innovative engineering teams are now able to use reliable real-time predictions by Monolith’s self-learning AI models to stay in the fast lane of highly competitive engineering domains.
- Users do not need to start from scratch. For example, an engineering team that has worked on refining a design for the last months around a narrow set of goals and constraints from other departments. What if these requirements suddenly change? Engineers will still encounter this issue with the use of traditional design exploration tools since the design requirements for optimisation campaigns need to be defined upfront.
- No iterative guessing games. How should engineering teams change a design to improve its performance? How can a team find an optimum when considering multiple goals and strict design constraints? These are the questions that engineers usually are failing to quantify and answer. Monolith enables engineering domain experts to use AI to make the product development process faster and smarter while fulfilling multiple optimisation targets. The result: Higher ROI, better quality products, and product performance in half the time.
No one knows your engineering data better than your engineers. Instead of hiring developers and waiting months for meaningful insights, Monolith’s team of aerodynamics engineers, software developers, and industry veterans have built a ready-to-use AI tool that is just right for you and your team of engineers.
Monolith accelerates the democratisation of self-learning models to magnify your engineers’ expertise, but not at the detriment of the programme, and test data to develop better quality products in half the time while enabling them to make product decisions at high speed and low cost.
"The most common mistake people make is that they hire data scientists without bringing the subject matter experts along. Successful application of AI is a marriage of data and expertise right down to the granular level."
Vincent Higgins, Global Director Digital Transformation, Honeywell
Analyse data and accelerate data engineering like never before with AI
By adopting AI into engineering workflows, dipping into your data lake, and utilising all new and historic data, companies can free up their engineers' time from admin-heavy data management tasks.
Your team of engineers can focus more on creating the most innovative and breakthrough products by using their historical data — something that every sector can benefit from, and something that every digital leader should know about.
Using Monolith to investigate test data, your team can combine, transform, and build self-learning models inside our easy-to-use AI platform that accurately and instantly predict intractable physical problems.
Named a Gartner Cool Vendor for AI in Automotive, Monolith is trusted by the world’s top engineering teams to build self-learning models that empower your engineers to do less testing, more learning, and develop better quality products in less time.