


What Type of Data Source Do Engineers Need for Machine Learning?
How can using artificial intelligence (AI) with different business data sources enable your team of engineers to optimise their workflows while your organisation saves money, uncovers new data insights, and gets better quality products out to market faster?
In this article, we will explore how AI can be used in engineering examples using different data points, data sets, and other data sources to drastically improve product development process techniques, as well as increase efficiency when compared to using a singular data source.
The Common Data Analytics Challenge
One challenge which engineering organisations face is generating accurate predictions during a given design cycle, and leveraging their data coming from various testing procedures under 10s to 100s of operating conditions. The impact and cost of errors increase significantly as the development workflow progresses.
Simultaneously, there is a much higher chance of a faulty design in the earliest stages of the process. Therefore, the data available to engineers at this stage is vital, and this is typically where AI and machine learning can improve the accuracy of these early-stage predictions.

What Is Machine Learning Data That Engineers Can Use?
Employing machine learning today, in order to reap the benefits of faster product design cycles and time-to-market tomorrow, requires data; from accumulated file data sources, new data from a singular database data source, or other data types.
Luckily, there are many data sources available for engineers to utilize coupled with various techniques and best practices for filtering data and getting the most out of it.
One thing any business and engineering leaders need to know about self-learning models is the importance of these multiple sources, including data lakes, and how they can be used to leverage past experience from engineers who might have retired already taking the precious domain knowledge with them.
What Is a Data Lake and How Can It Be Used for Data Analytics?
A data lake is a centralized repository that allows for data storage of all structured and unstructured engineering data at any scale (from big data to small datasets).
Data can be stored as-is in data lakes from one or more data sources without having to first structure the data.
This can be capitalised on later as the same data can be accessed to run self-learning models, improving business intelligence.

How Much Data Do I Need?
Now that we've talked about data sources, how much of it do we need to make accurate predictions? and many engineering leaders have approached machine learning with the following question: how much data is needed?
Whilst the value will depend on the amount of data available, the answer is that AI and data analysis can help the product development procedure at any stage, from having no data at all, to having access to big data.
High-Fidelity & Low-Fidelity Data Sources: Data Source Name Explained
When developing a product, there are many options when it comes to a data source, from quick rule-of-thumb estimates to real-condition testing of the product.
A high-fidelity data source is generally more expensive than a low-fidelity one. Thus, the higher the fidelity of the data, the lower the amount of available data.
Furthermore, whilst most engineering companies use more than one data source, most of the time there is little to no correlation made between the results of each data source - the perfect option to use AI to extract patterns from underutilised data.
The relationships between these different sources are often very valuable, and self-learning models can help fully exploit their relationships.
The Trial-and-Error Approach & Limitations of Data Sources
Before the days of simulation, the majority of products were developed by a trial-and-error approach, often involving a lot of testing.
For example, many prototypes were built until one fulfilled all the required criteria, which is still done extensively today if we think about the calibration of smart meters or crash testing scenarios.
Today, some companies still follow the path of solely relying on simulations as the ultimate solution ignoring that they may already have knowledge hidden in historic data from old testing procedures. There are two main reasons for this trend:
-
The cost of an error (time and money) increases a lot as the development cycle of a product progresses, thus introducing yet another tool seems to be too risky
-
The likelihood of a faulty design is much higher in the early stages of the development workflow, so an engineer might feel inclined to use established physics-based models rather than data-driven methods
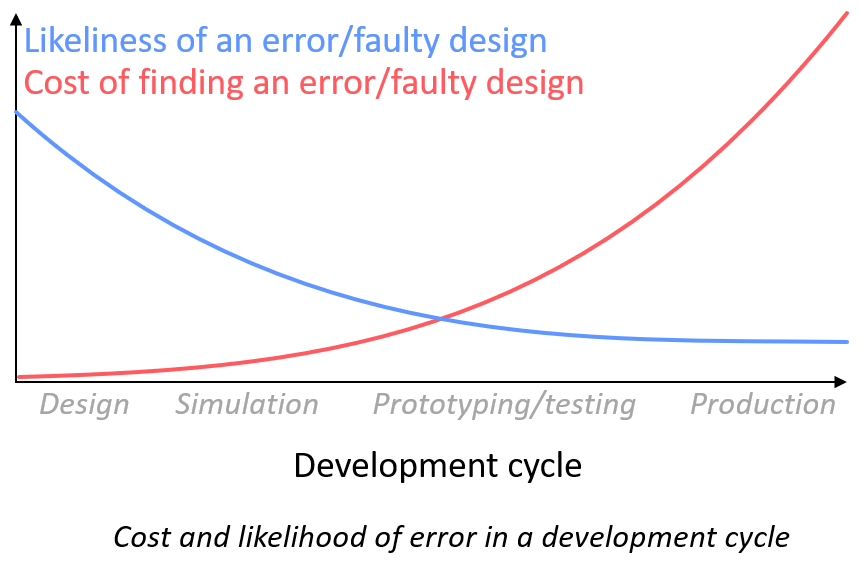
As a result, companies try to find as many errors and write off as many designs as possible at this early stage but are often limited by the computing power and accuracy of physics-based models that are often based on complex assumptions and require domain expertise in order to provide accurate results.
On the other hand, data-driven methods can facilitate the work of engineers by recommending the best designs and testing conditions to operate under very early in the product development process.
The Limitations & Accuracy of a Data Source
It is important to note the limitations of a given data source. There are two possible options:
-
A cheap data source, but with limited accuracy. There are many different examples of these types of sources, including mathematical equations, analytical or empirical models, 1D models for CFD predictions, numerical FE models with a coarse mesh, and many more. While the entire design space may be covered easily by the cheap model, there is limited accuracy, resulting in a limited understanding of product behaviour.
-
An accurate data source, but with limited availability. The source could be virtual (refined-mesh CFD and FE simulations) or physical and require prototyping (wind tunnel testing, track testing, and fatigue tests). While the results may be extremely accurate, there is a limited sampling of the design space. This also results in a limited understanding of the product's behaviour.
Data from testing procedures might not be cost-effective to produce at first, but companies in most industries often already have some historic data in hidden data lakes or can create data on the fly when doing the necessary testing, but leave out unnecessary testing scenarios in the long run.
Utilising test data with advanced predictive machine learning algorithms can improve the accuracy of the results beyond what would be achievable with the simplified model or simulations alone.
Applying machine learning algorithms to available data can dramatically increase the comprehensive understanding of product behaviour, compared to using cheap or accurate data sources alone.

AI to Enhance Your Current Development Process – The Power of AI
The power of AI is that it can detect extremely non-linear trends, as opposed to trying to build empirical functions to correlate multi-source data which is much less reliable. This enables engineers to solve intractable physics problems much more easily.
When people think about implementing AI into their product development workflow, they are often misinformed. A common myth associated with artificial intelligence is that it needs to replace the current tools in the development workflow. However, artificial intelligence can also be used to enhance the tools engineers already use.
Many intractable engineering problems may be too complicated to be perfectly modelled using classical deep neural networks. For example, failing to predict the sloshing noise of a tank design within the required accuracy is one example of such a case and would lead many to think that AI is completely unsuitable for the problem, eventually reverting to running costly and time-intensive conventional FE/CFD simulations. The opposite is the case!

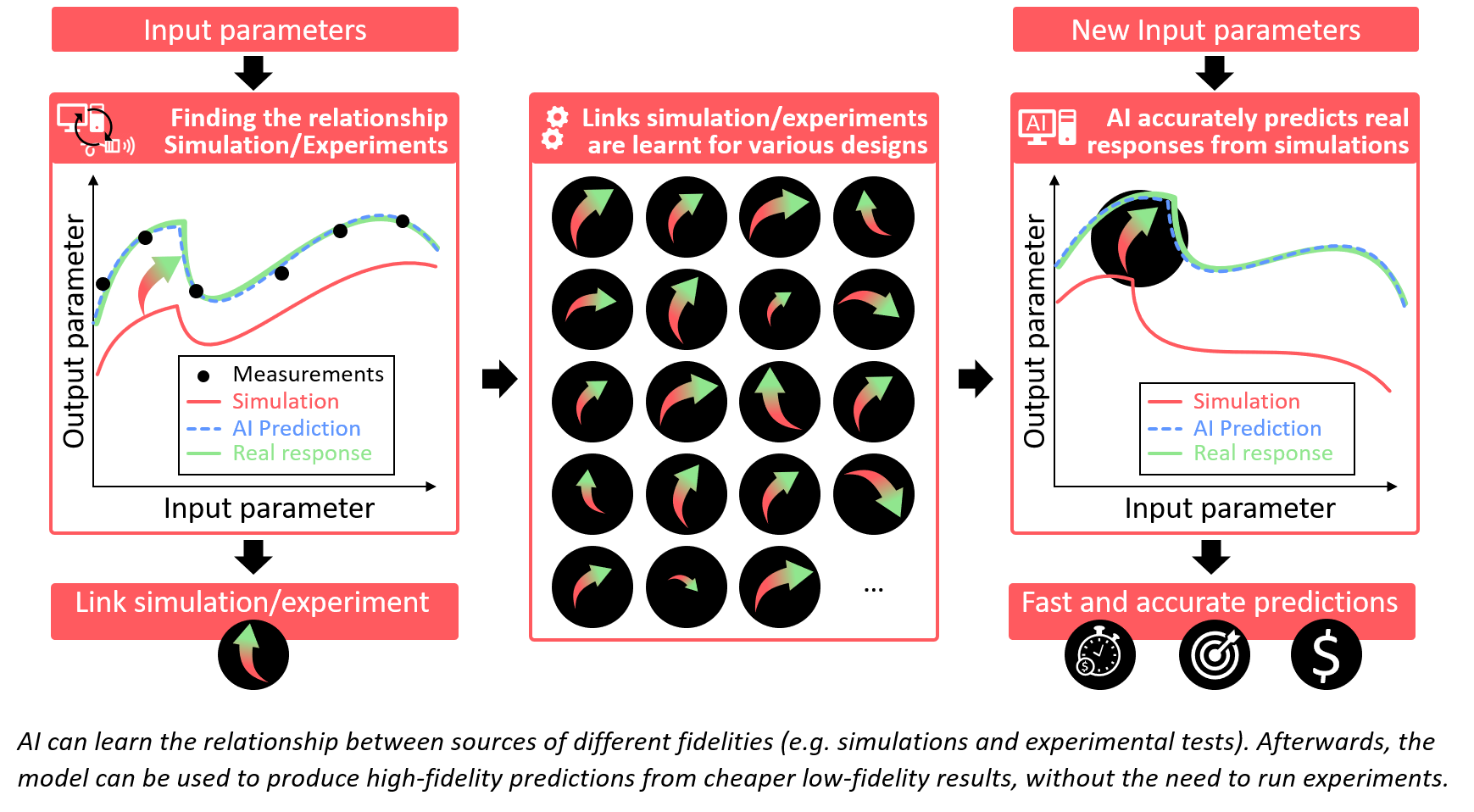
Self-learning models can use the current design data to predict how this design will perform in the real world, by knowing the previously-learned link between simulated results and the final actual experimental results.
This is shown below, where AI learns the relationship between different sources of different fidelities, such as simulations and experimental tests. Afterward, the model can be used to produce high-fidelity predictions from cheaper low-fidelity results, all without needing to run experiments.
The Business Impact of Using AI With Different Data Sources
There is a significant amount of positive business impact to be gained from using AI with various data sources as opposed to just one data source.
By utilising AI as a tool, engineers are able to save money in the product development workflow and create more value by getting products to market much faster while improving product quality.
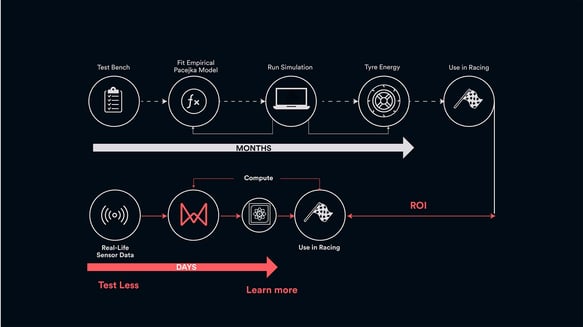
Top: The traditional, old workflow for a complex problem, based on empirical, known equations and physical models. Bottom: New workflow for an intractable physics problem that cannot be solved easily using the classical physics-based approach. Modelled and calibrated using Monolith’s self-learning models.
Cost Savings:
Using AI and employing machine learning tools with various data sources increases the strength of your data. Combining different sources through AI models allows your engineers to accurately predict the output, taking the best properties from each source.
Using AI and employing machine learning tools with various data sources allows engineers to predict how product designs will perform in the real world more accurately and faster than ever before.
This means engineers are able to create better-quality products while lessening or eliminating altogether costly testing processes. As every engineer knows, performing physical tests in an environment such as a wind tunnel is a huge resource expenditure, and in the traditional business product development workflow, multiple physical tests are needed to get the same results to ultimately produce high-quality products.
Therefore, it's a necessity to make at least use of one data source to reap the benefits of the implicit knowledge that’s embedded within the data, as this can effectively reduce the number of tests required as well as expenditures.
Another key thing to consider is the time and cost required by businesses to employ a data scientist to complete this work, who are also most often not engineering domain experts.
Faster Time-To-Market & Improved Product Quality
When using AI with more than one data source, engineers are able to link their low-fidelity results with high-fidelity results. This makes the data available to engineers much more powerful and empowers them to develop more meaningful insights.
This highlights how crucial it is to enable engineers with a no-code platform that does not require the user to understand deeply. This empowers engineers to develop products faster, with less time spent on the traditionally lengthy testing procedure.
An additional benefit of using AI with multiple data sources is that engineers are able to develop better-quality products; this is the main difference engineers can expect. Due to the data available to engineers becoming more insightful, they can have data analysts determine the best ways to improve products without incurring significant costs and time delays.
Through the clever use of AI and machine learning models on multiple data sources of varying quality and availability, engineers can better understand the behaviour of their products and consequently develop products of a higher quality.

Learn how AI was able to help improve smart meter system performance and reduce product development time by 25% (Control Engineering Article)
Conclusion: Combining Data Sources To Improve Engineering & Data Analytics
Designing, testing, and deploying complex, dynamic systems is fraught with risk, complexity, and unknowns.
With more accurate AI models, engineers can optimise their test plans around the factors that matter most, find design and test errors more quickly, and get the product to market faster with more confidence.
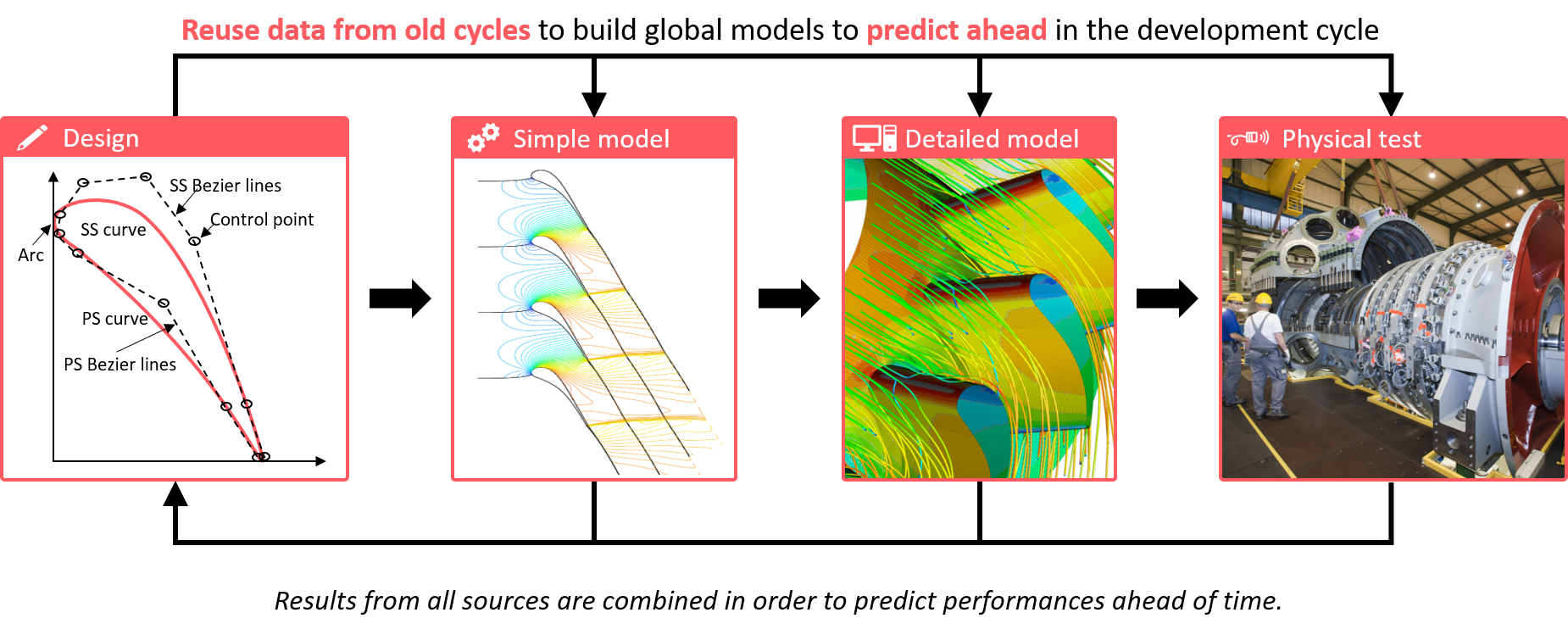
The accuracy of each prediction using self-learning models will increase as more data sources are combined, continually improving the overall value to engineers.
Many companies are already utilising artificial intelligence and machine learning as data analytics tools to improve their product development process, with immediately apparent benefits, new insights, and visible results.