


From noise to knowledge: engineering data for AI excellence
How the right tool transforms engineering data into actionable insights.
Engineering leaders from a wide range of industries including automotive, aerospace, semiconductor, and consumer electronics are looking to use Artificial Intelligence (AI) across the engineering process to speed development and improve efficiency.
However, these engineering leaders are learning that high-quality data is critical to realise the full potential of AI.
Despite massive investments in tools and infrastructure, collecting (the right) data and building a well-trained AI model remains a challenge.
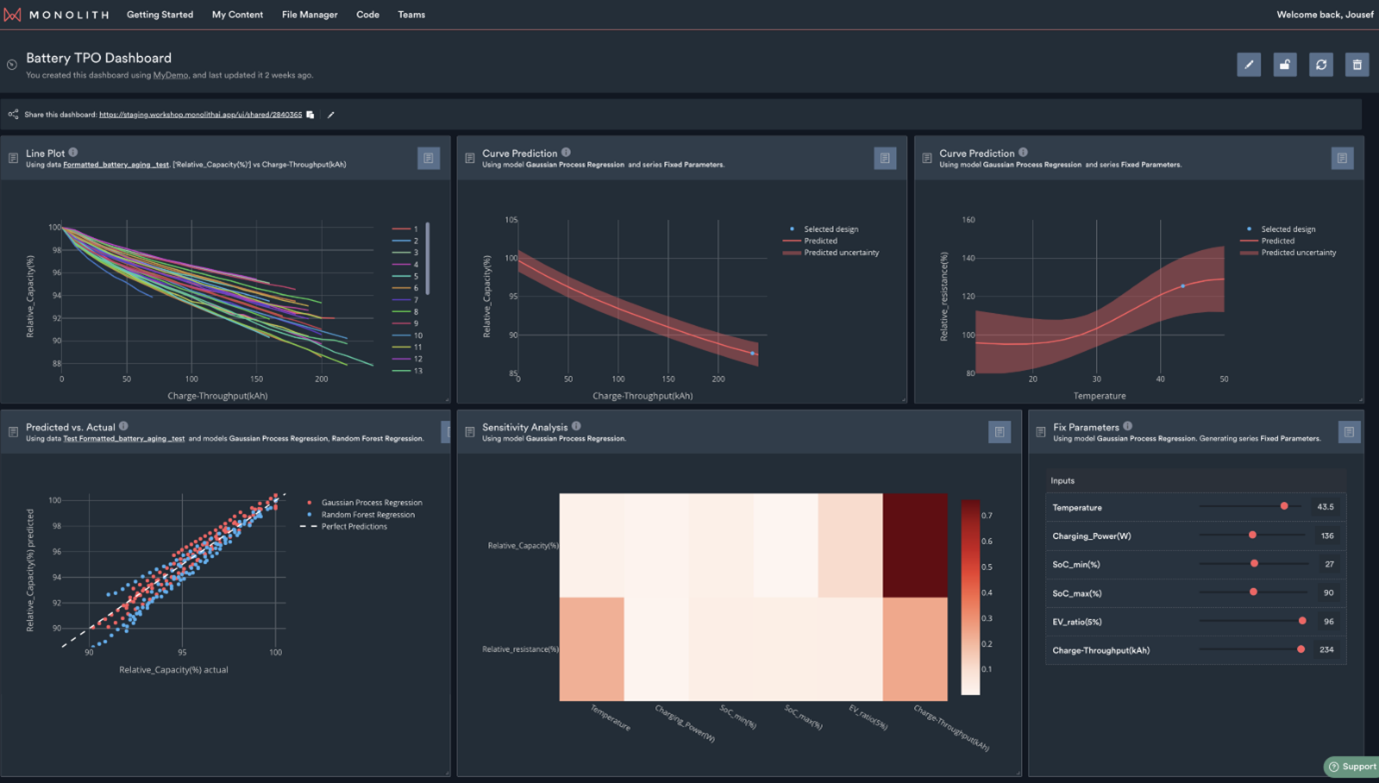
Improved battery models enable data engineers to make more precise predictions regarding battery performance across various conditions. These predictions can be readily explored in real-time by colleagues, departments, or customers through the collaborative Monolith dashboard.
Engineering leaders hope to adopt AI to accelerate new product development with smarter approaches to time-consuming and repetitive steps in the process.
For example, let’s look at EV battery development. With tremendous time-to-market pressure, safety concerns, and competitive threats, automotive companies are struggling to transition to electric vehicles.
Testing EV batteries has proven to be expensive and time-consuming to determine their performance characteristics and estimate how long it will last. It’s not uncommon for automotive companies to test hundreds of battery cells for many months as part of a new vehicle program.
With new machine learning (ML) techniques, researchers are discovering ways to significantly reduce testing times by as much as 30% to 70% while improving test coverage for battery validation at the same time.
Industry leaders hope to make these improvements a reality in real-world testing labs, leading to a rush to understand and apply AI and machine learning techniques in practice.

In this blog, we explore some of the most common data challenges faced by engineering leaders when considering AI and share some best practices from the Monolith Customer Success team, who have worked on hundreds of applications with some of the top engineering teams in the industry.
Make data a business priority
Engineering leaders are realising that their product data – from design tools, validation tests, and field use – holds the key to product quality, performance, and their competitive advantage if they can find a way to make it usable.
The engineering process for complex products in automotive, aerospace, or consumer electronics can spread across multiple teams, technologies, and facilities, making a unified view of the data challenging to achieve.
Under pressure to meet demanding performance and schedule milestones, teams can easily lose sight of the long-term value of the data they are generating within their specific stage of the process.
Companies must define a data strategy at the executive level that cuts across organizational boundaries if they are to be successful.
New, dedicated roles are needed to design data schemas, define data lakes, manage data ingress and egress processes, and ultimately make the data complete, findable, and usable to realize value.
Invest in data management processes and technology
Oftentimes, test data is generated in many different facilities using a wide range of test and measurement equipment and software tools.
Consolidating test data and making it usable for AI modelling requires a sophisticated approach to balancing local data processing and storage as each test stand is running and producing results, with a global plan for central storage in the cloud or on a server.
Aligning data sources and bringing them together to create a bigger picture can be a significant undertaking requiring technology partners to assemble a roadmap. Without executive leadership and vision, data strategy efforts can run out of steam.

Identify potential value up front
The most common question we get from leaders beginning their AI journey is “How much data do I need?” To properly answer that question, you need to start with the goal in mind – what business value are you trying to achieve?
Our Customer Success team conducts workshops with new customers to clearly define technical and business goals from their AI efforts, which are critical for informing your data strategy.
Your data requirements will vary widely depending on your goals. Some examples from our experience with customers:
- No Data: For customers starting on a brand new product design with no existing test data available for use in modelling, you should be strategic in defining what data to collect. With tools like the Sample Design Space function in Monolith, you can apply sampling methods to give you the best starting point for your test plan to cover the breadth of test parameters and parameter ranges.
- Little Data: Once you start testing a new design, you can use active learning techniques to analyze your test results and find the next round of test conditions required to fully test your design. Using Next Test Recommender, you can build your test plan as you go, starting with a small number of tests and iterating until your design is fully tested without running duplicate or unhelpful test conditions that don’t provide any new information.

Design data quality into your processes
Data quality assurance is crucial for identifying data quality issues in the early stages of the data pipeline, thereby reducing the cost and effort of remediation.
Although many of the mechanics of collecting and storing test data can be automated through technology, new roles, and processes are valuable for defining standards and ensuring compliance with them to make the data usable.
Let's delve into the specific standards that Monolith advocates for, ensuring the excellence of data used in AI applications.
- Storage standards: Efficient data storage is the bedrock of a successful AI project. Test data must be treated with the same rigour as business data from an IT systems sense, including access control, security, backups, replication, and tools for querying, updating, and extracting data.
- Data consistency: Consistency in labelling and metadata is a crucial aspect of data management. Often referred to as “Master Data Management,” schemas must be designed and maintained with standard lists of labels and values that will be consistent for describing different data fields or categorical data values. This is particularly important for product companies that manufacture many different permutations of designs. Managing product model numbers, feature sets, and test data so it can be properly interpreted after the fact requires discipline. Monolith has tools for transforming data in the platform, but the analytics and modelling steps are very late in the process. Companies with a clear focus on the value of their product data work up front to define, manage, and update data schemas as their business needs change over time.
- Completeness: No matter how carefully data schemas are designed or processes are followed, errors will result in missing, erroneous, or duplicate data being entered into your database. Monolith's platform equips users with the tools to identify and address missing data, enhancing the overall quality of the information fed into AI algorithms. However, a more central strategy of applying data standards during data import is a better approach to prevent duplicates or errors from getting into the system. No matter how diligent your team is in following standards to prepare data, you will need data engineering tools and processes to periodically check for data quality conformance or to transform data as new information is added.

Implementing these three key standards—storage efficiency, consistency of labels/metadata, and completeness—lays the foundation for robust data management and governance.
Monolith team's commitment to these standards is covered in its platform's capabilities, providing engineering leaders with the assurance that the data driving their AI initiatives is of the highest quality.
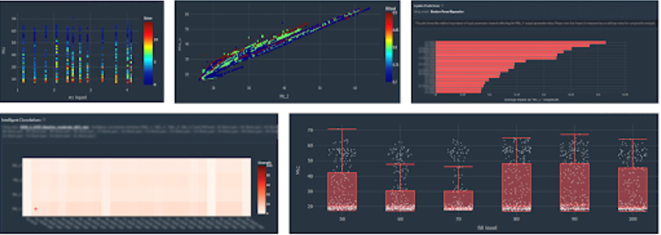
Monolith allows engineers to create a system for data sharing, accuracy maintenance, and information access while ensuring data security and privacy. Most importantly, a great and easy way for engineers to investigate their large datasets before manipulating them.
Now begin using data engineering tools
Once you are ready to launch into an AI effort, you can use the data importing, exploration, and transformation tools built into Monolith to process and prepare your data even more as part of the modelling process.
Conclusion
Data quality is not a one-time exercise but an ongoing process requiring continuous monitoring and improvement. Organisations must establish a data quality culture that fosters collaboration, communication, and transparency.
They should involve data stakeholders in the data quality improvement process, streamline data processing, share data quality metrics regularly, seek feedback for improvement, and include an expert to not only adopt an AI solution but, if already available, work on effective strategies that help create a data-driven culture that values data and data collection as a strategic asset.
Organisations can ensure data-driven decisions, reduced operational costs, and enhanced customer experience by investing in good data quality and a visionary AI strategy.
After committing to a data strategy, investing in tools and processes, identifying potential value, and designing in quality standards and processes, you are ready for large-scale, enterprise application of machine learning on your engineering data.
This blog post shares some high-level examples of best practices we have seen from the most forward-thinking companies looking to gain strategic value from their test data.
As engineering leaders navigate the complexities of their data pipelines and data storage, embracing these key elements becomes instrumental in adopting the full potential of AI for data processing.