


Data Quality & Availability in Artificial Intelligence (AI) in Engineering
There are various ways to gather data during product development, ranging from rough estimates and empirical laws to thorough experiments. However, obtaining high-quality data often comes at a higher cost than low-quality data. As a result, the more accurate the data is, the less of it it is available.
Additionally, although many engineering firms utilise multiple sources of data, they often do not consider the correlations between the results from these sources. By using Monolith’s AI models, it is possible to intelligently integrate multiple sources and take advantage of their relationships to obtain even more valuable insights.
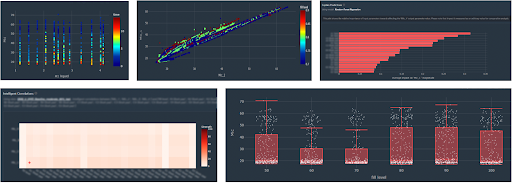 Figure 1: Data exploration inside of Monolith. One of the first steps in data preparation, and an easy way for engineers to investigate their large datasets before manipulating them.
Figure 1: Data exploration inside of Monolith. One of the first steps in data preparation, and an easy way for engineers to investigate their large datasets before manipulating them.
The Traditional Approach – Physics-Based Approaches
Historically, products have been developed using a trial-and-error approach, requiring the creation of numerous prototypes until one met all necessary specifications. These test campaigns are notoriously expensive for engineering companies owing largely to a heavy reliance on physical prototypes.
Figure 2 demonstrates two of the main reasons for the trend of using physics-based methods in the early stages of product development:
- The cost of an error (time and money) increases a lot as one goes through the development cycle of a product
- The likelihood of a faulty design is much higher at the early stage of development.
To save time and resources, companies aim to identify and eliminate as many errors and flawed designs as possible at the earliest stage, while still considering a wide range of design options.
Ideally, this is done before physical prototypes are created and the manufacturing process has been finalised. By doing this, they can avoid the costly and time-consuming process of testing products that do not meet the required specifications or certification standards.

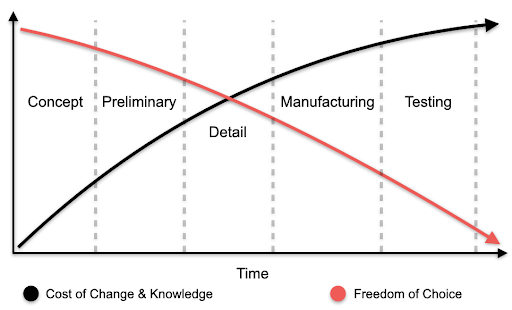 Figure 2: The Product Development Process – Cost of Change vs. Freedom of Choice
Figure 2: The Product Development Process – Cost of Change vs. Freedom of Choice
While some companies continue to follow this method, especially when prototyping is inexpensive, others, particularly in industries with high prototyping costs like aerospace and automotive, have shifted towards using physics-based simulations such as Computational Fluid Dynamics (CFD) or Finite Element Analysis (FEA) before building prototypes. One of the challenges with physics-based simulation methods is that they often rely on data that is very expensive to create in the first place.
.png?width=196&height=196&name=Bas%20Kastelein%20-%20Sr.%20Director%20Product%20Innovation%20(Honeywell%20Process%20Solutions).png)
“For the development of a new gas metre, CFD models were not accurate enough to capture the complexity of the flow for varying temperature conditions and types of gases. Using Monolith, we were able to import our rich test stand data and apply machine learning models to conclude on different development options much faster.”
-Bas Kastelein - Sr. Director Product Innovation (Honeywell Process Solutions)

Data Quality & limitations
One of the most pertinent uses of Artificial Intelligence in engineering is to conduct “virtual testing” based on underutilized test data.
Typically, test data is available from previous product tests, but engineers are often unclear whether this data can be of any value for a new project, not knowing that their existing data lakes are potentially worth millions, and can potentially be leveraged for the use of AI models which feed on that data. Monolith typically finds data available in two different forms when supporting development teams.
- High-Fidelity Data: This is typically highly accurate but generated at a significant cost. Sources range from physical testing to expensive simulations, delivering very accurate results but a limited number of data points.
- Low-Fidelity Data: Often, these are based upon methods that can generate results in large quantities, but the fit between reality and this data is of lower accuracy such as mathematical equations, an analytical model, a 1D model for a CFD prediction, or a numerical FE model with a coarse mesh. More often than not, the team has a mix of data that ranges between these two extremes.

The Challenge – Data Compatibility
The next challenge is the format of that data. While other AI tools for engineers lack support for many common data types used in engineering, Monolith supports a wide range of data types, making it simple for engineers to start feeding the system with the available information. The favorite is structured data but it is certainly not limited to that type. Typically provided in tabular form, such data is imported from common file types such as comma-separated values (CSV), Excel, text files, and even MATLAB.
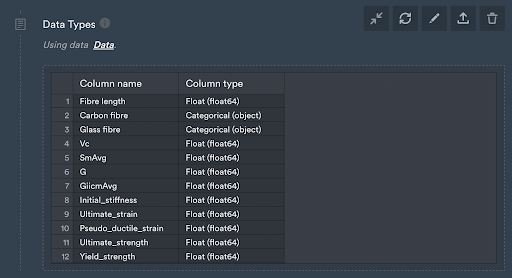 Figure 3: Monolith’s tabular importer detects and assigns the data type of each column automatically during the import process. You can use this function to check if the importer worked properly and if all columns have the data type you expected it to have.
Figure 3: Monolith’s tabular importer detects and assigns the data type of each column automatically during the import process. You can use this function to check if the importer worked properly and if all columns have the data type you expected it to have.
Another prevalent format is time series data. Applications tackling predictive maintenance, vehicle motion, or fuel sloshing noise prediction often fall into this category. A common issue here is the different sample rates of the data collected, but Monolith provides pre-processing tools and capabilities needed to bring these together on a common-time basis.
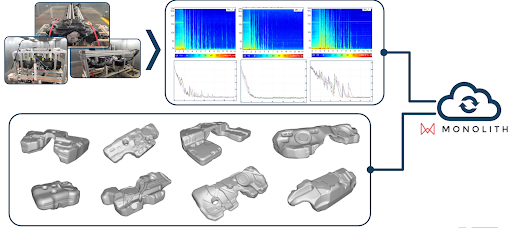 Figure 4: Reducing R&D iterations by empowering engineers & designers to assess the performance of designs themselves. Shown is a physical test setup to investigate the fuel sloshing behaviour of several tank CAD designs - done in collaboration with our customer Kautex-Textron (News Release)
Figure 4: Reducing R&D iterations by empowering engineers & designers to assess the performance of designs themselves. Shown is a physical test setup to investigate the fuel sloshing behaviour of several tank CAD designs - done in collaboration with our customer Kautex-Textron (News Release)
Many engineers are surprised to learn that CAD data can also be imported for use in Monolith. The modelling approach in the case study of Kautex combines acoustic test data, 3D CAD fuel tank shapes, and different inner component set-ups. This CAD-based approach using Autoencoders helped the Kautex engineers gain new and deeper insights into their complex products as well as the creation of a toolchain that provides valuable predictions significantly faster than what state-of-the-art simulations can provide. Both 3D and tabular approaches were used to train models and make predictions of sloshing noise behaviour based on new, unseen 3D designs of fuel tanks.

Mixing Data – Combining Different Sources to Improve Predictions
Perhaps the most crucial aspect to understand is that AI often benefits from a mix of data from a range of sources. As models are being built, they can take the best from all available data. For example, crash testing delivers data that can be compared to existing results of physics-based methods. Even data that is labelled as “not good” can ultimately be used to identify erroneous system behaviour when included in training of the AI model. When undertaking physical testing, results often prove accurate, but can result in significant errors due to the low number of data points. AI models can be very powerful as they can detect very non-linear trends, whereas trying to build empirical functions to correlate multi-source data is much less reliable and not as universal.
An AI model can take the best from multiple data sources and can even be used to surpass and outperform physics-based methods such as CFD to more accurately predict the output than the classical CFD approach in isolation, only by using existing test data.
By adding datasets of lower fidelity, AI can learn the relationship between the different levels of data accuracy, thereby improving its performance using what can be described as a type of multi-model calibration. In the context of vehicle configuration simulations, low-fidelity test results for a new design could deliver good predictions thanks to the model’s accurate understanding of how such data impacts high-fidelity simulation results.
Artificial Intelligence to Enhance R&D Processes
AI does not need to replace your current tools or disrupt your existing workflows to be valuable: it can also be used to enhance them! Some complex engineering problems may be too complicated to be modelled perfectly by AI with the current amount of data. Going back to the example of a car. If your AI model fails to predict the drag within the required accuracy, you might think that AI is unsuitable for the problem and revert to running conventional FE/CFD simulations, fair enough!
You might not be able to make perfect predictions of the drag of your car with individual datasets, but AI can still be used to link between the different available sources. Combining sources of different fidelities could allow AI to predict accurately the car behaviour, by learning to link the low-fidelity results to the high-fidelity ones. Think of this as a sort of multi-model calibration. The relationship could be learned by an AI model for different car configurations or even between different cars. For a new unseen configuration, a low-fidelity simulation and the trained ML model could be combined to predict a high-fidelity result. AI models can use the current design’s test results to predict how this design will perform in the real world, by learning non-linear patterns between physical quantities and geometric features for example.
Conclusion
So, for those still on the fence regarding drawing upon AI models for their development approach, yes, AI models still demand high-quality data as a machine learning model is only as good as the data it is fed. But, as described, this doesn’t always mean millions of data points from a single source. In fact, it is often preferable to have a diverse range of high and low-fidelity data that AI can use to improve overall prediction accuracy. While Monolith’s users often draw on traditional data sources, such as tabular and time-series or even 3D CAD, these data types can also be relied upon to deliver impressive results. The accuracy of such predictions will increase as more data from different sources are collected during development and testing cycles making use of the self-learning nature of these models.