


Author: Lukas Innig, Principal Researcher Physical AI, CoreWeave
Read Time: 12 mins
We pointed an internal LLM agent at MLE-bench's tabular tasks. With no human in the loop, it won two gold medals and ranked first of 27 agent systems, including 1 of 685 on a materials-science problem.
If you spend any time around the people building physical AI (surrogate models for CFD, materials property prediction, fleet anomaly detection, generative engineering) you notice something the broader ML conversation has mostly stopped talking about. Almost all of this work, at the layer where a model actually meets the data, is tabular. A DoMINO surrogate sits on top of mesh descriptors flattened into a tabular feature matrix. A crystal property model sits on top of composition and geometry descriptors. A fleet anomaly detector sits on top of sensor telemetry. The exciting headline architecture is one part of the stack. The unglamorous tabular layer underneath it is what most engineering teams actually maintain.
So we ran an experiment to answer one question: on real tabular ML tasks, how far can an agent get on its own, with no human in the loop?
We built an LLM agent internally: a frontier model paired with a structured set of tools for inspecting data, building features, training models, and reading out-of-fold results. We pointed it at the tabular slice of MLE-bench, OpenAI's benchmark of real Kaggle competitions. It ran on public data only, with no leaderboard feedback and no human in the loop during the run. Across the four tabular tasks the agent took on, two ended in gold medals and three finished above the Kaggle median. Overall, it ranked first by average task rank against twenty-seven comparable agent systems, with a headline result of 1/685 on NOMAD, a materials-science task that asks the model to predict formation energy and bandgap of transparent conductors from crystal composition and geometry.
NOMAD is the same shape of problem an automotive aero team solves when they fit a surrogate to CFD output, or a battery materials team solves when they screen candidate cathode chemistries. The agent reached the top of the leaderboard end to end, running on a single NVIDIA L40 GPU on CoreWeave that cost a few dollars to spin up. We think this is the part of the ML story worth paying attention to right now.
Tabular ML is the workhorse of physical AI
The story everyone has been telling themselves: deep learning ate the rest of ML, foundation models ate deep learning, and the long flat plateau of tree-based models (XGBoost, LightGBM, CatBoost) stopped being where progress lived. Around 2023, most ML conference talks were about transformers, and the median Kaggle competition started looking like an anachronism.
That story isn't wrong about algorithms. The marginal return from a new gradient-boosting library is small. Put a 2018 XGBoost and a 2025 XGBoost on the same features and the gap between them is mostly engineering. The tabular modelling curve flattened years ago.
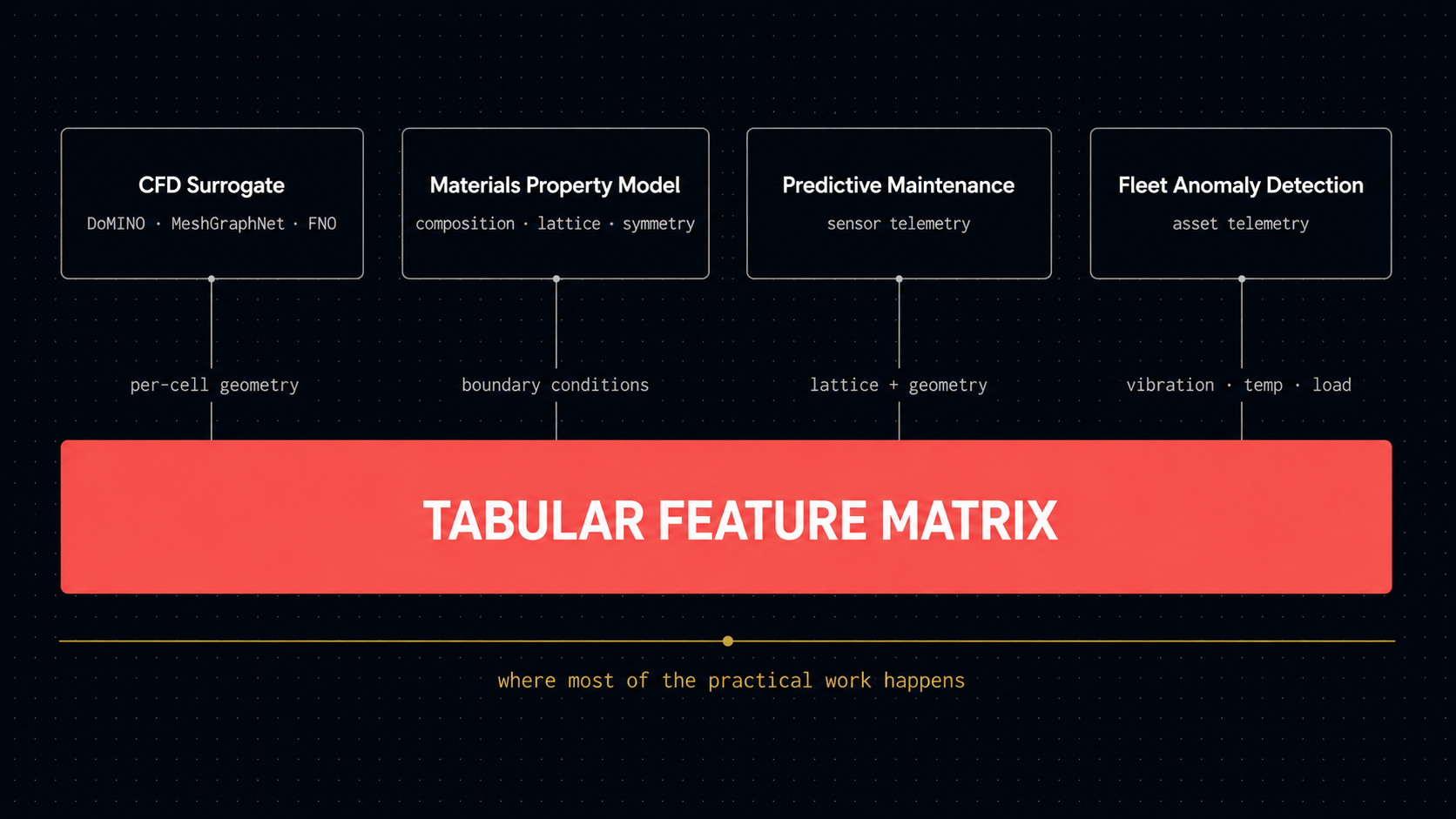
But algorithms aren't the workload. Take any concrete physical-AI problem and follow the pipeline down to the layer that does the actual prediction. A CFD surrogate model (DoMINO, MeshGraphNet, FNO) needs training data, and the training data is per-cell or per-node descriptors of geometry, boundary conditions, and simulation state. That is a tabular feature matrix. A materials property model takes inputs that describe composition, lattice, symmetry, and local geometry. Those inputs are tabular too. A predictive maintenance system needs sensor telemetry: tabular. An anomaly detector on a fleet of physical assets - same. Even when there's a heavyweight architecture at the top, there's almost always a tabular layer underneath that has to be built well, and that layer is where most of the practical work happens.
"What everyone missed, while the foundation-model news cycle was running, is that the tabular layer was the bottleneck and the bottleneck was human."
The real bottleneck in tabular ML was human, not algorithmic
If you've ever sat next to a Kaggle grandmaster on a tabular problem, the rhythm is roughly this: they pull up the data and notice that one column has fourteen percent NaNs and another has values clustered around five suspiciously round numbers. They build a feature, run a quick LightGBM with three folds, look at out-of-fold predictions, notice the model is bad on a specific slice, build three more features targeting that slice, and run again.
On a hard problem, the loop is twenty cycles deep, and each cycle takes a thoughtful person somewhere between twenty minutes and an hour. The model itself does almost no work, because it's the same XGBoost call every time. What scales is the thinking: the hypotheses about why a dataset behaves the way it does, the willingness to try a feature that probably won't help, the discipline to throw it away when it doesn't.
An AI agent runs the feature-engineering loop 60 times overnight, for a few dollars
An AI agent with the right tooling, that is, the ability to inspect data, profile distributions, build features as durable assets, train a model, score it, and look at out-of-fold predictions, can run the same loop. It runs it differently, with different blind spots. But the economics shift in a way that matters for any team hiring data scientists faster than it can train them. Twenty cycles of human attention is, conservatively, a week of senior engineer time. Twenty cycles of agent work is a few hours of structured compute. Each individual cycle the human runs is better, because a senior engineer is more discerning about which features will help.

But the agent compounds: sixty cycles overnight, on four datasets simultaneously, with the marginal cost of one more cycle near zero. The expensive resource in tabular ML stopped being human attention and started being structured GPU compute, which is exactly what CoreWeave's cloud is built to provide.
The agent isn't smarter than the grandmaster. It's just cheap enough to try things, which turns out to be most of what the grandmaster was doing, and trying things turns out to be most of what the grandmaster was doing. Call it AutoML if you want; the older term doesn't really cover what these agentic workflows now do, which is the open-ended reasoning part of the loop, not just hyperparameter search.
An autonomous agent ranked 1 of 685 on NOMAD, a materials-science task
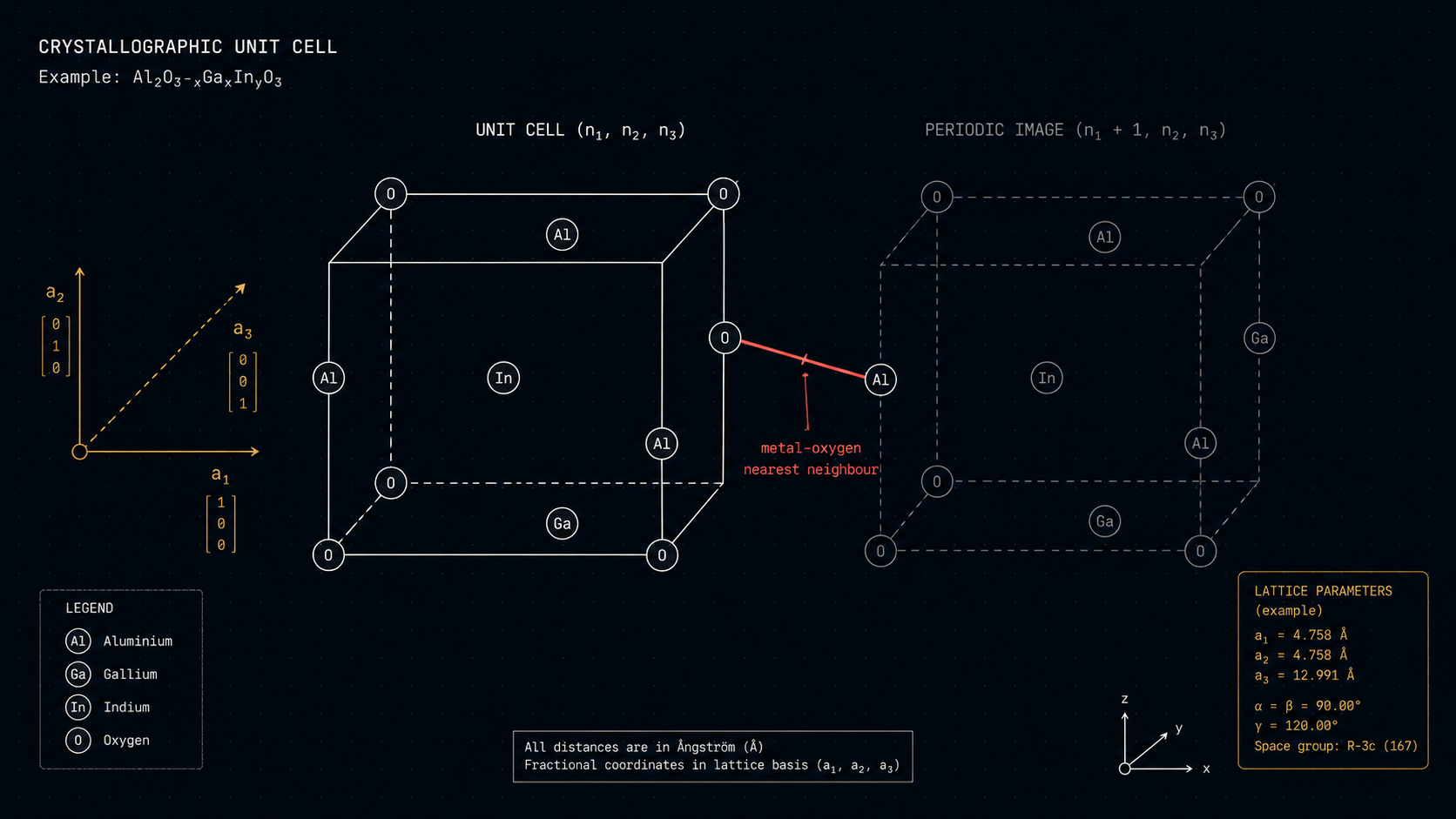
Pick one competition to make this concrete, and pick the one that looks most like real engineering work. The NOMAD 2018 task on MLE-bench is a materials-science problem: predict two properties of a hypothetical transparent semiconductor (formation energy per atom, and bandgap energy) from the material's composition and crystal structure. The dataset covers around 3,000 candidate (Al, Ga, In)-oxide materials, split into a public training set of roughly 2,400 rows and a test set of around 600. Each row gives the spacegroup (one of 230 crystallographic symmetry groups), the cation fractions for Al, Ga, and In, three lattice vector lengths and three lattice angles, and the total atom count. Each material also has an associated geometry.xyz file listing the actual atomic positions inside the unit cell. The Kaggle gold threshold is an RMSLE of 0.05589. The median is 0.06988. The original competition was won by teams that spent weeks on this.
Here is what our agent did, unprompted, in one run.
It started by reading the task description, then inspecting the train and test CSVs and the sample submission to lock down format and target. It noticed the data shape and the per-material geometry files almost immediately. Then it spent most of its cycles building features.
It built composition features: counts and fractions of each metal, total atom count, an entropy-style mixing score, and aggregate atomic properties (atomic number, mass, electronegativity, radius, ionization potential, valence). It built lattice and density-style descriptors: cell volume from the three lengths and three angles, density from total atoms over volume, and shape descriptors capturing how cubic or tetragonal the cell is. It parsed every geometry.xyz file, extracted the per-atom positions and labels, and computed pairwise Cartesian distance summaries. By this point the feature matrix had grown to 449 columns.
Then it did something a human materials-ML practitioner would recognize as the actual move. Crystals are periodic. Two atoms on opposite sides of a unit cell aren't far apart; they're bonded across the boundary. Raw Cartesian distances misrepresent the chemistry. So the agent went back and added periodic-boundary minimal-image distance descriptors, recomputing nearest-neighbor distances under periodic boundary conditions and pulling out metal-to-oxygen nearest-neighbor distances specifically. Its own justification, written into the transform summary, was: "local bonding/coordination under periodic cell, especially metal-oxygen nearest-neighbor distances, is more physically meaningful than raw Cartesian pair distances." That isn't a feature you build by accident. That's domain reasoning.
How the agent built 677 features and cleared NOMAD's gold threshold
The feature matrix grew to 677 columns. The agent then trained an ensemble of LightGBM, XGBoost (CUDA), and CatBoost regressors on log1p-transformed targets, with 5-fold cross-validation built on the raw public training distribution before any cleaning. It selected non-negative blend weights per target by minimizing out-of-fold RMSLE. The submission went through prediction sanity checks (row count, finite values, target range) and was written out.
The final score on the private test set was 0.04853, against a gold threshold of 0.05589 and a median of 0.06988. Rank 1 of 685 valid public agent submissions for this competition. The agent did what a materials-aware engineer would have done, in one run, with no human in the loop, on a single L40 GPU.
What's interesting about this kind of work is what it wasn't. The agent didn't sweep model families, and it didn't tune hyperparameters at scale. It reasoned about the physics of the dataset, built features that reflected that reasoning, and used a structured CV loop to select among them. That is the same shape of work that wins automotive aero competitions and battery materials screens, and it's the part our research team spends most of its time thinking about, because that's where the leverage is.
MLE-bench tabular results: first of 27 agent systems, two gold medals
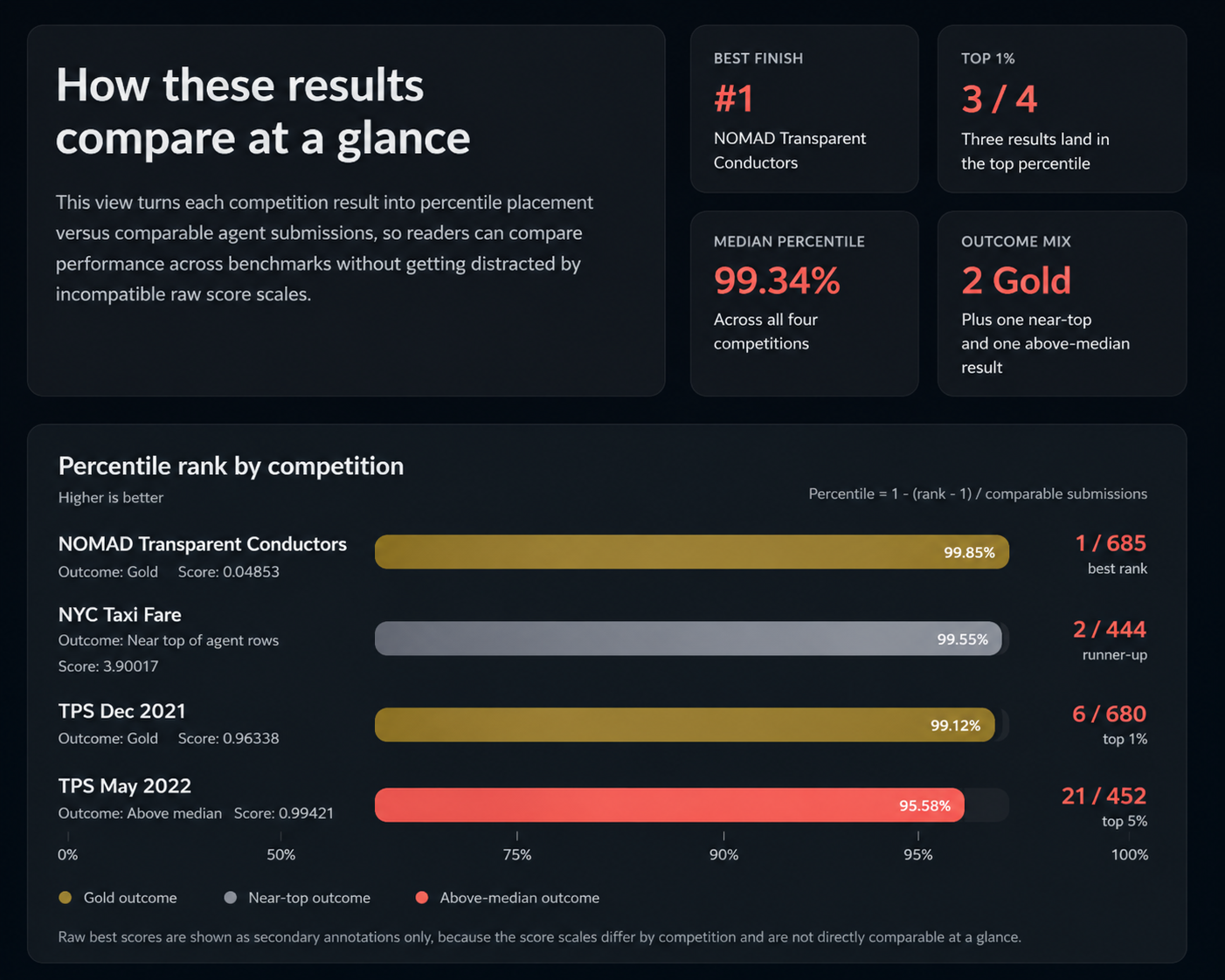
The agent's results answer that question two ways: against the human Kaggle entrants who originally entered, and against the other agent systems benchmarked on the same tasks. It held up on both. Across the four tabular tasks:
|
Competition |
Best score |
Outcome |
Rank vs comparable agent submissions |
|---|---|---|---|
|
NOMAD Transparent Conductors |
0.04853 |
Gold |
1 / 685 |
|
TPS Dec 2021 |
0.96338 |
Gold |
6 / 680 |
|
TPS May 2022 |
0.99421 |
Above median |
21 / 452 |
|
NYC Taxi Fare |
3.90017 |
Near top of agent rows |
2 / 444 |
The agent took two gold medals and finished three of four above the Kaggle median. The fourth, NYC Taxi, sits below the Kaggle gold threshold of 2.83377 but at rank 2 among published agent results on that dataset, which is the more useful comparison until autonomous machine learning is competitive head-to-head with grandmasters.
Despite the datasets being old, MLE-bench has been the standard benchmark for ML-engineering agents, with new submissions arriving as recently as early 2026, including systems built on this year's frontier models. Our agent ranked first among all of them. These are the tabular problems engineering teams still solve every day, and the expert work behind a top result is becoming something you can automate and make more available.
(TPS is Kaggle's Tabular Playground Series: synthetic-tabular monthly competitions used as common reference points.)
Across the 27 comparable agent groups that produced valid submissions on all four tasks (excluding entries that used test-set feedback during the run), the agent ranks first by average task rank, at 7.50. The next closest groups (Famou-Agent 2.0 / Gemini-3-Pro at 12.00, an o1-preview AIDE run at 18.00, PiEvolve at 43.75) all match the agent on medal count, but our agent’s distribution of ranks is better. The win isn't a single lucky spike; it's consistency across every task in the slice.
What the agent got wrong: tool ergonomics, not model quality
The interesting failure mode wasn't bad models. It was bad ergonomics.
Tabular ML platforms typically give the agent a Python escape hatch. In our case, it's data_agent_tool_transform_dataset_python, which lets it write arbitrary code over the data. It's there for the cases where the structured tools don't cover what the agent needs: a weird parse, a one-off cleanup, a domain-specific calculation. The periodic-distance feature in the NOMAD vignette was built through this tool, and that's the right use of it.
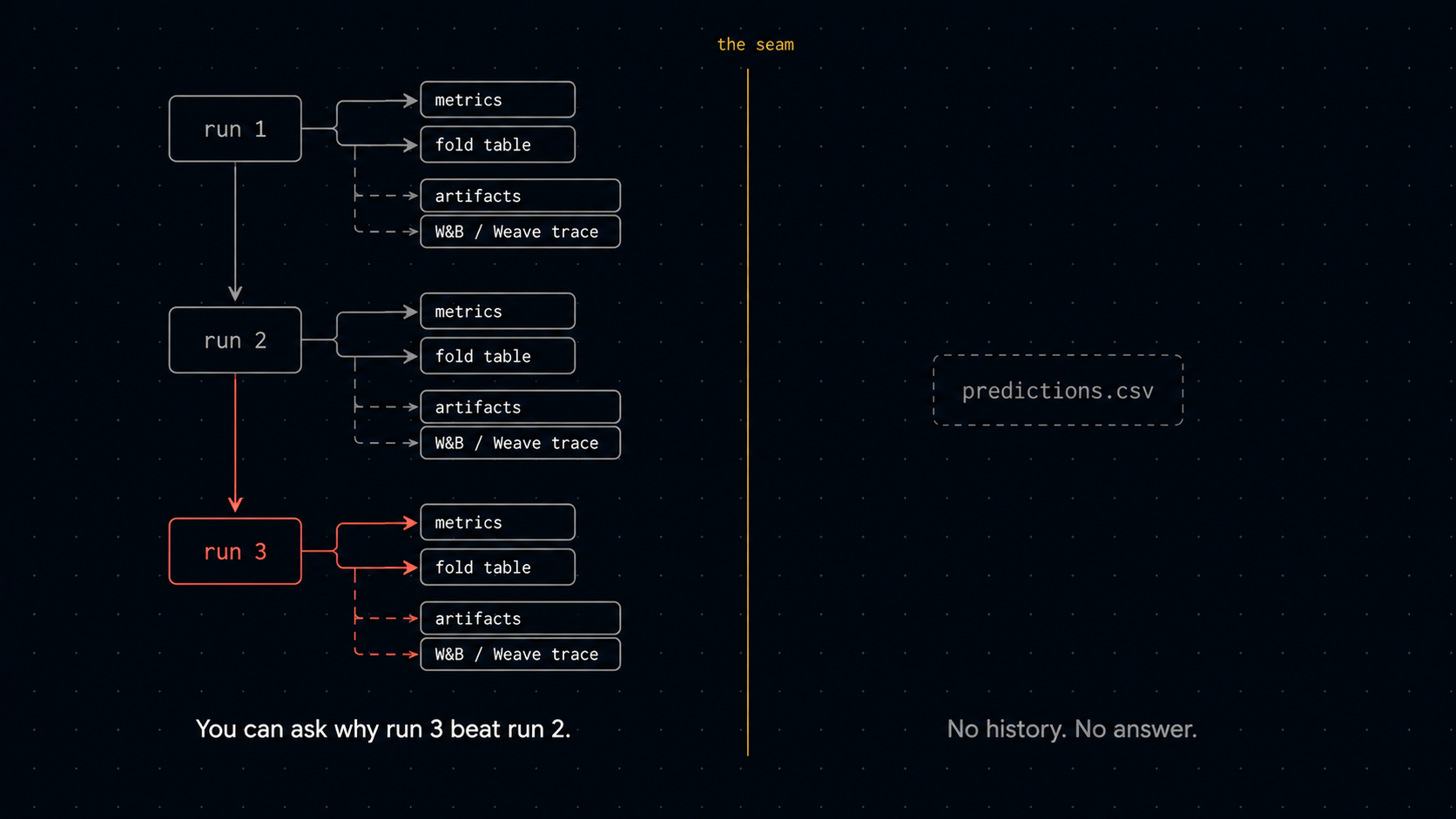
What we observed, repeatedly, was that the agent would also use this tool to train models. Not because it had to. Because it could. Once it was already inside a Python cell, the path of least resistance was to import LightGBM, fit a model, and emit predictions, instead of going back out, calling the structured train_tabular_model tool, and getting metrics, fold tables, model artifacts, and Weights & Biases/Weave traces emitted automatically.
The submissions from that path scored fine, but the work was harder to inspect, harder to reproduce, and harder to compose. The structured model tool emits a complete artifact lineage; the Python-cell path emits a CSV. When you ask "why did this model do better than the previous one," the structured path has an answer. The escape-hatch path doesn't.
The fix was a prompt change. The current prompt now reads, verbatim: "Do not hide model selection or benchmark training inside data_agent_tool_transform_dataset_python; model-tool runs produce the repeatable metrics, assets, and W&B/Weave traces we need." And the agent now respects the seam.
The lesson is worth carrying into any agentic system doing real technical work: what the tool surface lets the agent do is what the agent will do. If your structured tools are well-shaped and your free-form Python tool is a backstop, you get repeatable work. If your free-form tool is the easiest path to a result, you get one-off scripts that happen to work. For benchmark submissions it doesn't matter; for anything deployed against your own engineering data, it matters a lot.
The no-cheat boundary: how the run avoids data leakage
Worth being explicit about, because this is where benchmark posts usually go off the rails: the agent never saw private labels. The CoreWeave runner mounts the public prepared data only. Private labels stay on a local machine. Grading happens locally after submissions are synced down. The prompt explicitly warns the agent: "Never use hidden/private evaluation feedback as a tuning signal." Model selection is by public out-of-fold metrics only.
The reason this matters isn't just methodological hygiene. It's that this is the same boundary an engineering team would draw in production: the agent operates over the data it's allowed to see, holdouts and evaluation stay on the team's side, results come back as predictions and a traced artifact bundle. The benchmark posture and the deployment posture are the same posture. That parity is the thing that makes this result transferable to private data (which is what your team would actually want to run it against).
Autonomous tabular ML is now real enough for physical AI teams to use
Three claims, in order of how confident we are.
First, the headline. Autonomous tabular ML, by which we mean an agent that takes raw data and a target and produces a competitive model with no human in the loop, is now real enough to do at the top of the published leaderboards on real Kaggle competitions, including ones that look like materials-science. Not on toy problems. Not with a human picking features. On NOMAD, on TPS, on NYC Taxi, end to end, on a public benchmark, with the same no-cheat boundary a customer would draw.
Second, the implication for the way physical-AI teams currently operate is large. Most engineering organizations have a small data-science function and a lot of domain expertise that doesn't have time to write feature engineering code. An agent isn't a replacement for the team; it's a junior collaborator that doesn't get tired and can run sixty cycles overnight. The team brings the domain hypotheses ("the failure rate is driven by thermal cycling, not by absolute temperature") and the agent does the iteration ("here are 30 candidate features that encode thermal cycling, here's the cross-validated impact of each, here's the best blend"). The leverage is enormous because the current bottleneck is almost always cycles of attention, not modelling skill.
The third piece is the infrastructure. Fast structured compute is what makes this work. The agent has to load data, profile it, build a feature, train a model, read the out-of-fold predictions, and decide what to try next, all in minutes. Stretch those steps to hours and the loop stops being useful.
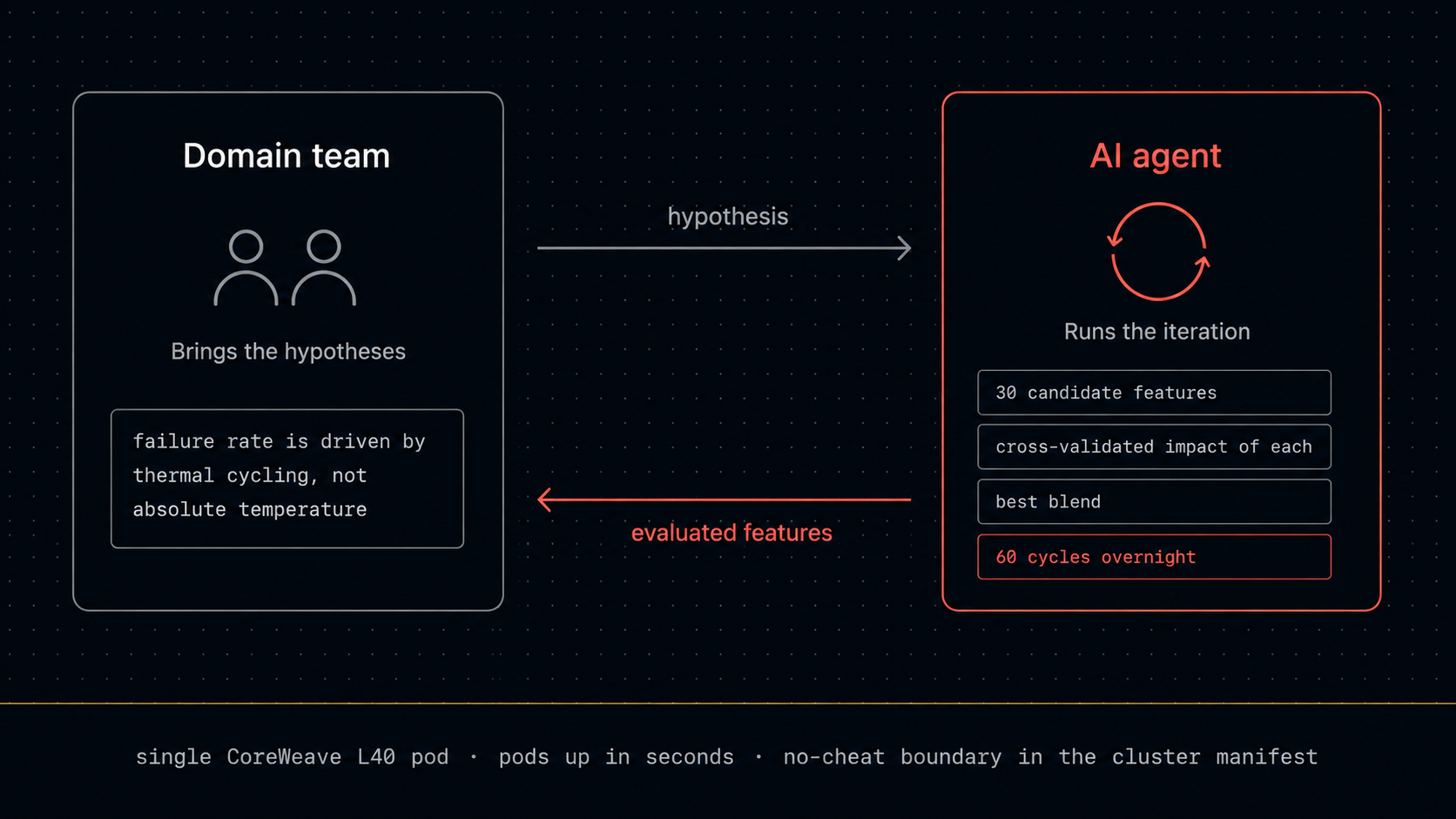
We ran this on CoreWeave. The NOMAD result came out of a single L40 GPU pod on CoreWeave Kubernetes Service with 15 to 30 vCPU, 48 to 160 GiB of RAM, and S3-compatible object storage. Pods come up in seconds. Per-experiment cost stays low. The no-cheat boundary is written into the cluster manifest as policy, so the agent never reaches private labels.
Four MLE-bench competitions across independent GPU lanes was a Tuesday afternoon experiment, not a quarter-long project. That is the operational shape physical AI teams should plan for.


Where autonomous tabular ML goes next
The next pass of this work is mostly about reproducibility and breadth: multi-seed runs for each competition so the result isn't a single lucky lane, full artifact lineage so every winning submission has a complete trace, and a wider set of tasks so the medal count generalizes beyond four. We'll write that up when it's done.
The longer arc is more interesting. Tabular ML never went anywhere.
There was just a long, quiet wait for the bottleneck to move. It's moving now. The work that used to take a team of data scientists weeks is starting to take an agent an afternoon on a single GPU pod, and the work that looks most amenable to this shift is, by no accident, the work physical AI runs on. That's the part to pay attention to.
About the author

Lukas Innig is a Principal Researcher in Physical AI at CoreWeave, responsible for blending mathematical rigour, applied data science, and agent design to bring autonomous problem-solving to complex engineering work. He partners with research and product teams to build AI agents that are scoped, reproducible, and grounded in how engineers actually work, crafted with a practitioner's perspective that makes frontier AI dependable enough to put into production.