


Are self-learning models the key to unlocking engineering potential?
Artificial intelligence (AI) solutions have achieved much in the past decade, seeping into all corners of our everyday life.
Some of these AI solutions offer easy convenience, such as voice assistants. Other AI tools support checking grammar and formulation of the written (or typed) word. Newer AI technology can even generate ideas and text copy to assist humans in their content creation process, such as ChatGPT.
Most of the AI in use today is trained through a technique called supervised learning, a method of teaching models to produce the desired output using a labelled training set (see Figure 1). The training set includes input and correct output pairs, allowing the model to learn over time. The algorithm's accuracy is adjusted until the error is minimised.
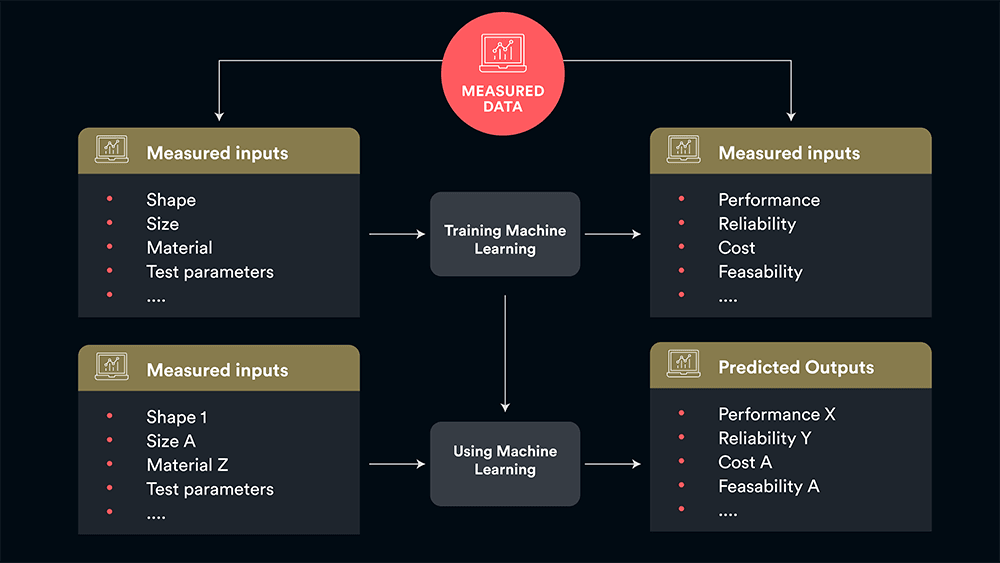
Figure 1: The supervised learning process - the training data provided to the model works as the supervisor that teaches the machine to predict the output correctly. Once deployed, users can provide a set of new parameters for unseen scenarios and can thus predict the output in a “virtual test”.
Now think back to how you first started to learn about the world around you as a child. Everyone has a good grasp on gravity, even those born long before Newton formulated gravitational theory. As we learned to grasp objects and pull ourselves up to stand, then walk, we undertook a series of unplanned experiments that furthered our understanding and respect for gravity. This ability to learn without recourse to scientific instruments, or falling apples, is considered self-learning.
Obviously, an in-depth and fully rounded understanding of gravity is best attained through education, using words, equations, and other knowledge transferred from expert to student, which comes later in life after childhood. Yet, as a toddler-to-be short on language skills, self-learning is the only available method — and this concept is also applicable to AI.

What is a self-learning model?
In a nutshell, self-learning models are AI models that, once deployed, can be optimised by training them on data that becomes more available over time.
This process prevents engineers from having to begin building new AI models from scratch every single time they collect more data.
Self-learning models are strong enablers for AI adoption, as they allow engineers to capture and structure (historical) data.
Moreover, new data can improve the self-learning model on an ongoing basis by systematically recording the design characteristics, test conditions, and test results.
As new data is systematically collected by tests, self-learning models improve with the augmented wealth of knowledge provided, which makes model predictions become much more accurate and accelerates verification and validation cycles.
The lifeblood of self-learning models: data
Many industries have access to masses of data, both new and historical. The aerospace sector is a classic example where historical data is available. As long as data has been digitised in the correct format suitable for the algorithm, it can be imported to train a self-learning AI model.
For engineering applications, AI self-learning models involve image, or most often 3D or tabular data (e.g. time series data) from test stands. Businesses operating in markets such as industrial and automotive sectors are also likely to have access to significant quantities of data thanks to the increasing number of sensors in use or other captured data to meet specific certification or homologation standards.
However, such data needs to be prepared before using it to train an AI self-learning model (see Figure 2). For patterns and trends to be found, the data needs to be labelled. In some cases, the labels may already be apparent. For example, data from automotive sensors will be listed together with the units for the recorded values.
 Figure 2: Data exploration inside of Monolith AI software - one of the first steps in data preparation, and an easy way for engineers to investigate their large datasets before manipulating them.
Figure 2: Data exploration inside of Monolith AI software - one of the first steps in data preparation, and an easy way for engineers to investigate their large datasets before manipulating them.
Data scientists usually provide their self-learning model with the labelled data, training it to improve its accuracy at detecting the wanted features. However, this is a laborious process. Data quality is the first issue, with the team spending much time cleaning or pre-processing the dataset of mislabeled data.
After each round of testing, changes to the dataset may be required to push the AI model closer to the desired result. As the task grows in complexity and the quantity of data multiplies, the process becomes slower and more laborious.

How do self-learning models work?
In the world of engineering and science, development is typically iterative (see Figure 3). For example, if a vehicle is driven around a test track to determine the impact of the suspension on handling, one set of data for a handful of setups is generated.
Should the testing be repeated a few weeks later, the team will want to use these new results to improve the performance of the existing AI model, not start training a new one with the holistic dataset.
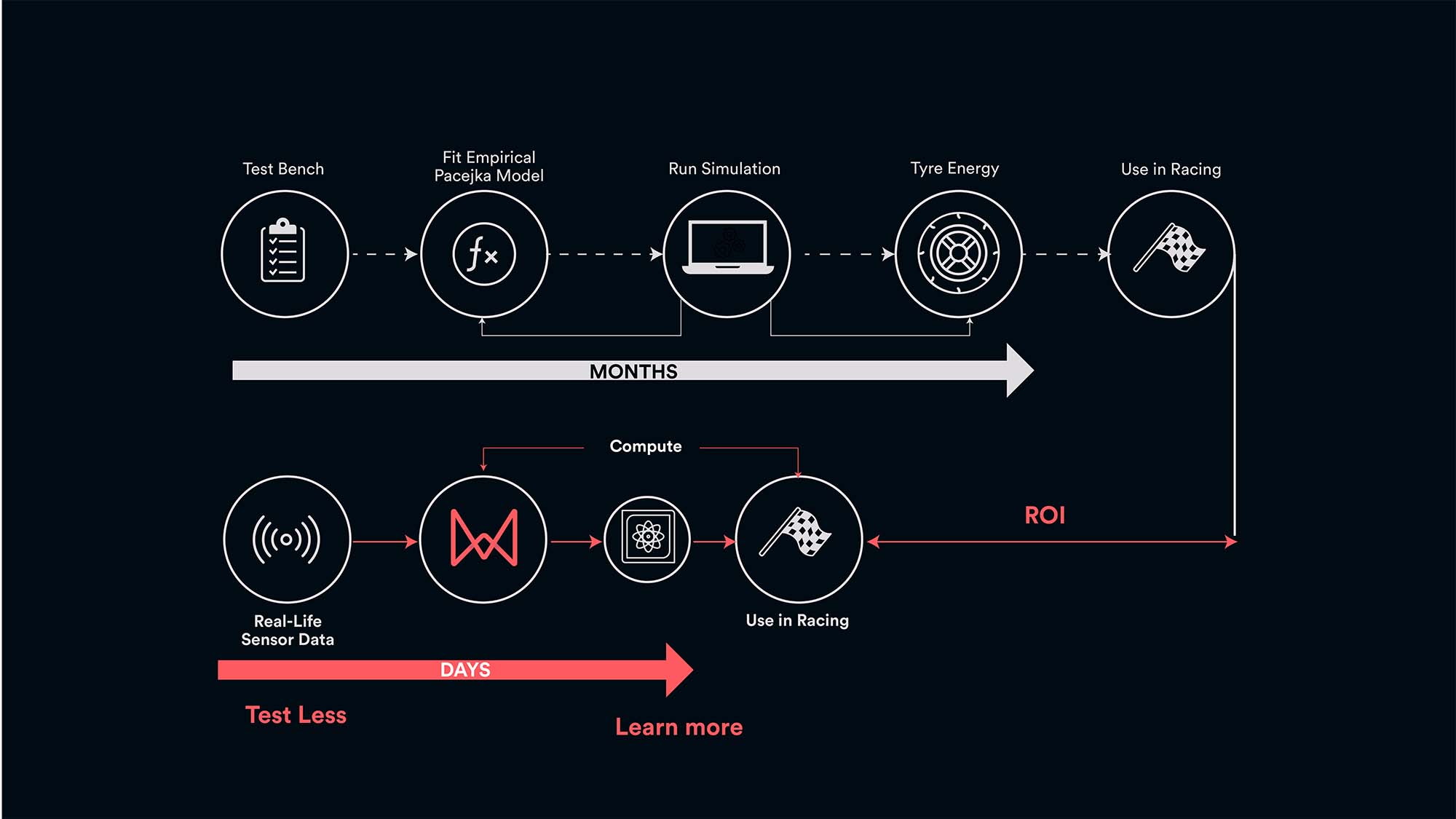
Figure 3: Top: The traditional, old workflow for a complex problem, based on empirical, known equations and physical models. Bottom: New workflow for an intractable (non-linear) physics problem that cannot be solved easily using the classical physics-based approach. Modelled and calibrated using Monolith’s self-learning models.
In the first step, the AI model determines the key features of the dataset, generating an overall understanding of relationships within the data. In the second step, the model applies self-learning to finetune its capability for the assigned task. While not the same as human learning, it is closer to the combination of experience coupled with formal education through which we learn about gravity, as highlighted earlier.
What is a self-learning model best used for?
One of the key advantages of this approach is that the self-learning model learns to fill in the blanks, as the name would suggest. Depending on the use case and type of data, AI can learn from intractable, nonlinear systems even when only small quantities of data are available.
This makes self-learning models well-suited to tackle engineering challenges where, frequently, the only available data comes from testing of a handful of early prototypes. Self-learning is also highly supportive of preparing the data and models that can be transferred to new designs, allowing the AI model to adapt as new data is added or it is applied to a new task.
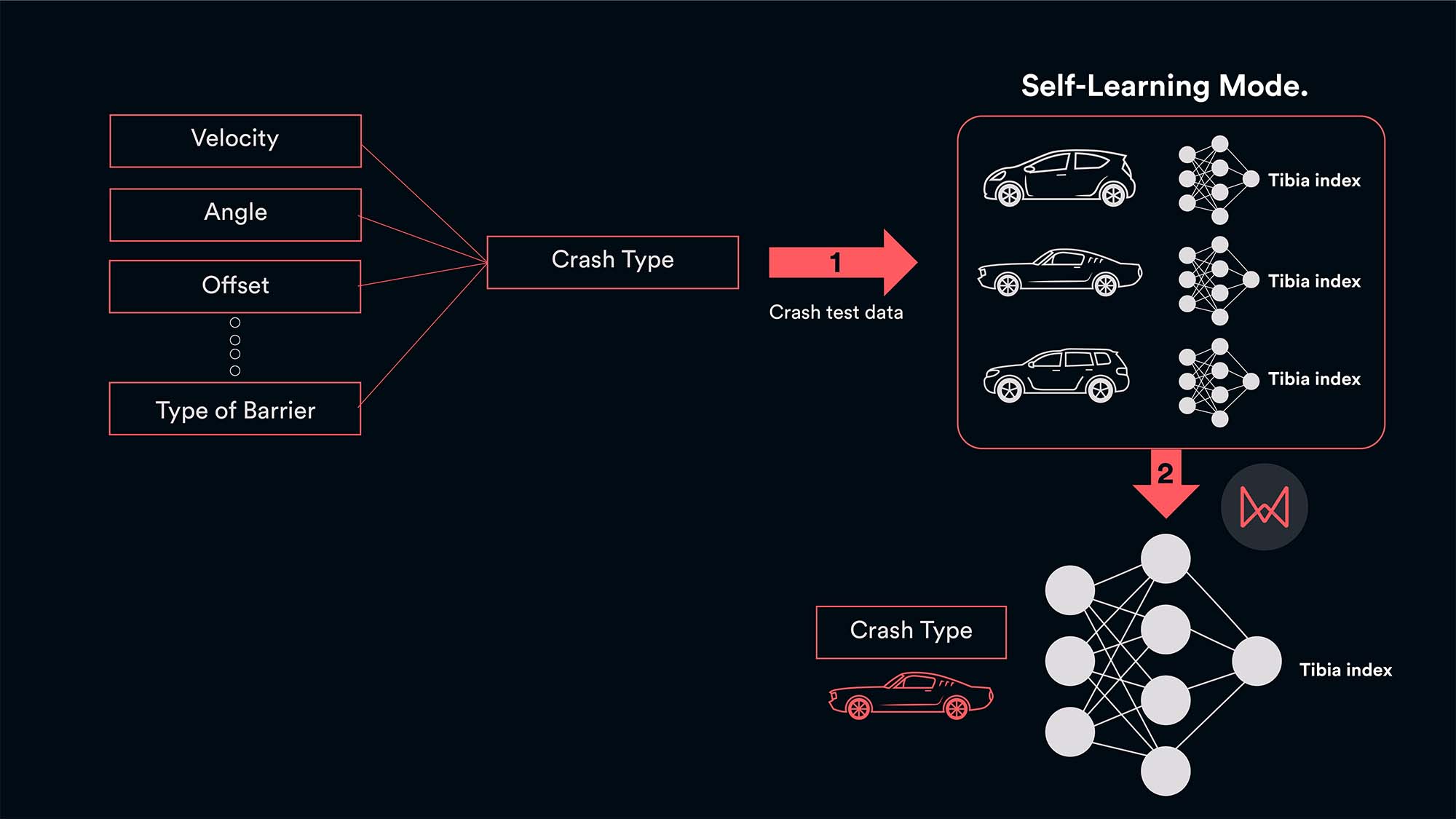
Figure 4: BMW engineers’ current crash development uses 1000s of simulations as well as physical tests to capture performance. By building self-learning models using the wealth of their existing crash test data, the BMW R&D engineering team was able to accurately predict the force on the tibia for a range of different crash types without doing physical crashes.
The applications for self-learning AI models are broad and already enable engineers to:
- Make better-informed decisions on how best to operate their complex products in new scenarios (Jota Sport: Case Study)
- Use less test data to more accurately calibrate products or systems across a full range of operating conditions, so that they can correct themselves automatically (Honeywell: Case Study)
- Have confidence in making optimal use of testing time, with AI recommendations for the best next conditions to test in (Video: Wind Tunnel)
- Minimise time spent producing erroneous data or investigating the health of a large pool of sensors, by quickly and automatically identifying faults in your system (Kistler: Case Study)
Customers using Monolith have reduced the number of iterations needed to optimise vehicle design parameters, while Honeywell shortened the time required to calibrate their gas metres. A process that would often take 18 months to ensure the calibration error was below the legally required 1%. With AI, that time is reduced by 25%.
Can self-learning models learn anything?
While the progress in the world of AI is rapid and exciting, we’re still a long way off from AI that knows it all, also known as Artificial General Intelligence (AGI).
What we can say is that the state of development is such that AI can be applied to a wide array of previously intractable physics problems. Teams that have previously tried to build simulation models or solve complex equations to describe their system suddenly have a new tool at their fingertips.
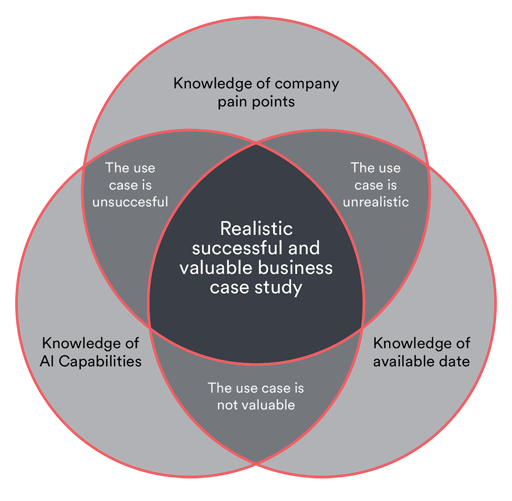
Figure 5: Only when knowledge of pain points, available data, and AI capabilities come together, a realistic and valuable business case study can be defined to achieve a positive ROI for a business.
Naturally, there is some initial resistance to using or employing AI solutions. AI is still largely considered to require massive amounts of data, which many engineering teams are short of. However, the self-learning AI tools offered by Monolith have resolved some of the most intractable challenges on significantly limited datasets.
Based on Monolith's experience with previous and current customers, successful use cases require some knowledge (see Figure 5), but by working with our dedicated and experienced team, you may find that a solution to your previously intractable problem is now on the horizon.
From asking "what is a self-learning model" to adoption
Many engineering companies have already adopted AI and Monolith’s self-learning models to minimise their R&D effort in the verification and validation stage of the product development process.
However, adopting these self-learning models does not simply involve building and deploying them. To take full advantage of this AI solution at scale, it will need to fit into your overall engineering workflow, without disrupting it.
Here are a few guidelines that Monolith learned working with customers on how to ideally adopt a more data-driven workflow that will benefit your company and enhance your engineers’ capabilities.
Several reasons that contribute to inefficient traditional engineering workflows:
- Knowledge isn’t being retained. The results of physical tests carried out during development aren’t being captured properly, meaning very little knowledge is being retained for future generations of designs, developed by future generations of engineers.
- It often feels like a guessing game. How should you change your design to improve its performance? How does your design react to operating conditions that have not been tested before? How to find an optimum when considering multiple parameters, performance goals, and strict regulatory constraints? These are the questions that engineers are often failing to quantify and approach by using their intuition.
- You often need to start from scratch. Your team has worked on refining a design for the last months around a narrow set of goals and constraints from other departments. What if these requirements suddenly change? It can mean going back to square one. You will still encounter this issue with the use of traditional design space exploration tools since the design requirements for optimisation campaigns need to be defined upfront.
- It involves a lot of manual effort. Because of the iterative nature of traditional engineering workflows, a lot of an engineer’s time is spent setting up repetitive, time-intensive or empirical testing, analysing and preparing reports for one result at a time, and trying to align with other departments despite the uncertainty of how changes in the design will affect its quality or performance.
Make no mistake. No engineering company can adopt AI at scale overnight. It takes time to go from asking ‘what is a self-learning model?’ to integrating them seamlessly into your workflow. It requires proper adjustments to your engineering workflow, including setting up a repeatable processes to generate and capture data from your tests.
This can present an important upfront investment but our experience with customers has shown that after initially setting this up in collaboration with Monolith and adopting these new ways of working, overall R&D effort quickly reduces in subsequent design cycles.